Faster Than a Missile: Intercepting Content Fraud
On May 21, 2020, thousands of Israeli websites were hacked by a group called “Hackers Of Savior”, probably including hackers from Turkey, The Gaza Strip, and North Africa. Not the first – and surely not the last – cyber-attack of its kind, the hackers targeted websites stored on uPress, an Israeli web hosting company.
The websites’ content was replaced by a page with a statement against Israel – “The countdown to Israel’s destruction began a long time ago” – and a disturbing video clip. The attack was timed to coincide with the Israeli national holiday “Jerusalem Day”, which celebrates the reunification of the city after the Six-Day War. It also coincided with the Iranian “Quds Day”, which was probably an additional motivation for the attack.

Beyond the visual corruption of the websites, the attackers also tried to delete all the websites’ data. Besides, the hackers prompted the browser to ask the viewer’s permission to take their photo with their computer’s webcam.
This attack was not your ordinary run-of-the-mill fraud event. It did not revolve around the usual advertiser-sourced content fraud. Rather, the source of the problem was an outside party and Outbrain was not even the target. The attack harmed not just the website publishers and end-users, but advertisers too.
Before diving in to see how Outbrain coped on the battleground during this event, let’s start at the beginning. What is “content fraud”, why is it such a challenge, and how does Outbrain protect its network and partners every day?
Content Fraud – The Major Challenge for Content Networks
Content fraud is an industry-wide problem that comes in many forms, including phishing, redirects, cloaking, malvertising, conspiracy-mongering and fake news. The internet is subsumed by an endless amount of fake content, such as fake quotes, doctored images, and deepfake video, making it increasingly difficult to navigate towards an authentic online experience. As content fraud is always evolving, it becomes much harder to detect and prevent over time.
As a discovery company, part of Outbrain’s lighthouse is to provide qualified content to its readers. While the overwhelming majority of content provided by advertisers is qualified, interesting and safe, Outbrain invests significant resources to ensure that no malicious or deceitful content makes its way onto our advertising platform.
When content fraud is detected, it comes from a specific and identifiable source that can be easily blocked and prevented from accessing Outbrain’s network. Generally, we use multiple technologies and people-powered techniques to verify that advertisers are legitimate and promoting qualified content. We look at a variety of properties, the identity of the advertiser, and the content itself. Based on the technologies Outbrain usually uses, the ability to respond is broad and fast.
In the recent event, the challenge for Outbrain was different.
Why and How Did Outbrain Respond to the “Hackers of Savior” Cyber Attack?

The cyber event of May 2020 presented our anti-fraud specialists with a different and unique set of obstacles.
Firstly, we were not battling against an entity that was part of our network. The threat did not come from one of our partners – rather, our publishers and advertisers were first in the line of fire.
Secondly, the attack was broad and not sourced from a specific website. We assumed that some websites in our network had been corrupted, however, we didn’t know which ones. Targeted and specific blocking is the most common anti-fraud solution, yet in this case, we had to find and block multiple domains that were yet unknown.
Thirdly, any action would be temporary. When we identify a fraudster on the network, they are permanently blocked and banished from the network. There is no going back. However, in this case, we knew that once the affected websites recovered, we had to immediately re-enable them and permit them back on the network.
Lastly, even though Outbrain was not the target, we had to stay on our toes, and to assume that the attack was still happening or could happen again at any time. Although we identified the characteristics when it occurred, we had to be ready to quickly detect any new method or pattern that the attackers could develop and deploy.
The response by our anti-fraud team was designed to protect all three pillars of the Outbrain ecosystem:
- The first pillar – Users who need protection from threatening content.
- The second pillar – Advertisers who need protection from being charged for harmful visits and damage to their brand image.
- The third pillar – Publishers who were prevented from directing traffic to threatening content that would harm their reputation.
The Technology Challenge
In order to find the corrupted sites, we had to scan loads and loads of web pages. Once such a page was found, we had to disable it immediately so it would no longer be promoted on the Outbrain network. These scans had to be done quickly and repeatedly. If a cyber attack is ongoing, pages can be hacked even after we scan them, and if the pages have recovered, we need to know straight away in order to recommend them back to the network.
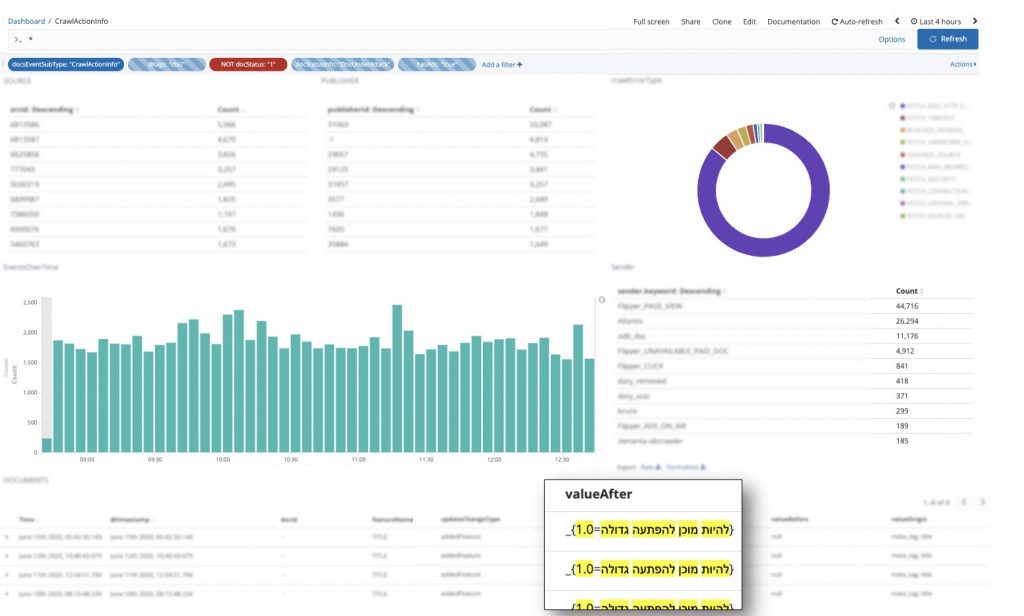
How did we identify a hacked page? We had a few options:
- Published lists of the hacked websites: In some cyber attacks, this can be a good solution, but not in this case. The attack was a rolling one, which meant not all the websites were hijacked at once. There was no single reliable source that contained all the hacked websites.
- Third-party solutions: In order to maintain the integrity of the Outbrain network, the Anti-Fraud team uses not only internal solutions that were developed in-house, but also external solutions, to flag problematic content, like malware, cloakers, redirects, and other fraud types. A third-party solution can be used to classify specific characteristics as a website “under attack”, so it might have been an option in a case like this. However, making the adjustments necessary to detect this specific attack would take too long, and in this instance, the ability to react fast was super important.
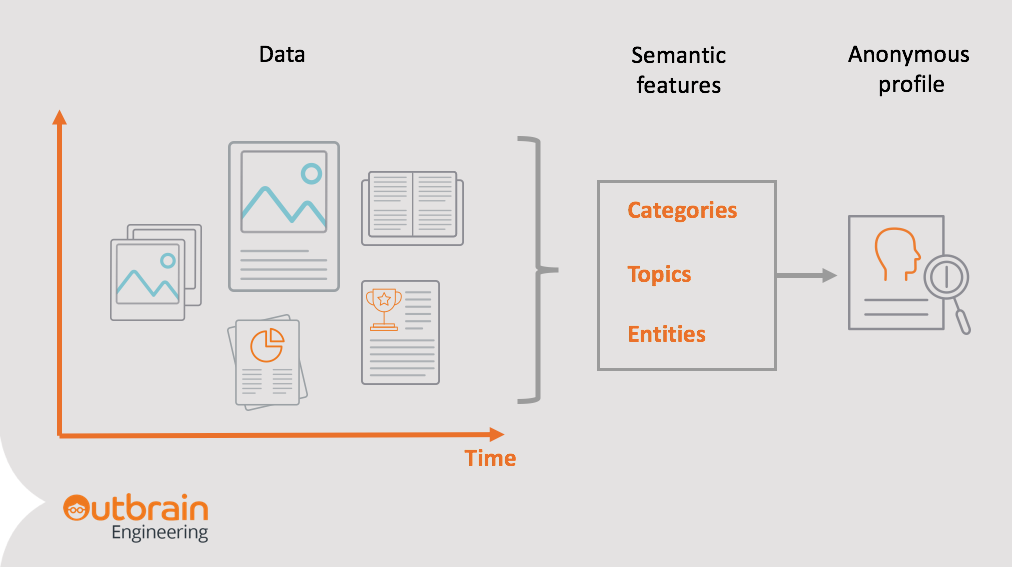
- Outbrain’s in-house crawler: In order to recommend the best content to readers, Outbrain crawls the promoted content in its network, analyzing characteristics and extract features that will be used in the NLP and recommendation algorithms. Our in-house crawler was identified as the ideal solution for this challenge, as it is already connected to our databases. In order to get immediate results, we only had to define the population we wanted to crawl. Moreover, with some additional configurations and quick development by the AppServices team, we could tackle all the challenges at once, automatically, and rapidly.
Crawling Our Way Out
So Outbrain’s in-house crawler was immediately mobilized for detecting which sites were hacked.
We started by analyzing several hacked sites found in multiple sources across the net. Using our crawler output logs, we discovered that the pages were identical in terms of both structure and visual content, meaning they shared the same attributes (title, text, links, keywords, etc.). By querying the crawler logs for those attributes, we were able to easily identify more hacked domains. The problem was that the picture we saw was only a partial one, since not all the pages were crawled yet.
We chose the relevant potentially-hacked domains list and set it to be crawled in cycles of 3 hours, using a configured crawler feature that was specially tailored for this problem. Once the crawler identified a new (specific) value for the attributes the attackers injected into the web pages, we could disable the hacked pages. Disabling a page meant that the hacked native ads were no longer available as recommendations on the Outbrain network, and were no longer accessible by our users.
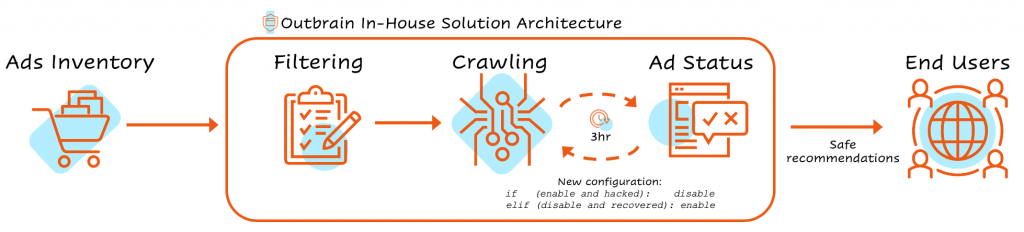
The ongoing scans also allowed us to monitor and understand the impact of the attack on our inventory in real-time and to communicate it to our partners. When web pages were recovered from the cyber attack, we used the crawler to re-enable them on the Outbrain network. With the help of our unique tech capabilities, we were able to come full circle out of this pernicious cyber attack.
Rapid Response Saves the Day
The attack began on the morning of May 21. According to uPress’s announcement, by May 22, 02:28 (Israel Time), 90% of the websites were recovered. As a result of our actions, we were able to prevent Outbrain users from being exposed to hacked web pages containing disturbing content.
This rapid reaction not only protected our users from threatening content, but it also enabled affected publishers and advertisers to return to their usual Outbrain traffic services very quickly after websites were recovered.
What Doesn’t Kill Us, Makes Us Stronger
During the cyber rescue operation, we were in direct contact with several teams in the organization, enabling us to present a united front and a holistic solution. Along the way, we benefited from the ability to pivot in several different directions as necessary, both internally and externally. It was a great lesson about how to use various tools to solve an array of problems.
With the rapid, coordinated response from Outbrain’s teams, we overcame the “Hackers of Savior” attack, and also developed the infrastructure to manage similar cyberattacks in the future, if – and when – they occur.