Back in May 2017, I was scheduled to speak at the DoTC conference in Melbourne. I was really excited and looking forward to it, but fate had different plans. And lots of them. From my son going through an emergency appendicitis operation, through flight delays, and up to an emergency landing back in Tel Aviv… I ended up missing the opportunity to speak at the conference. Amazingly, something similar happened this year! Maybe 3rd time’s a charm?
The post below is the talk I’d planned to give, converted to a blog format.
August 13, 2015. Outbrain’s ops on call is just getting out of his car when his phone rings. It’s a PagerDuty alert. Some kind of latency issue in the Chicago data center. He acks it, figuring he’ll unload the groceries first and then get round to it. But then, his phone rings again. And again.
Forget the groceries. Forget the barbecue. Production is on fire.
 18 hours and many tired engineers later, we’re recovering from having lost our Chicago datacenter. In the takein that follows, we trace the root cause to a single network cable that’s mistakenly connected to the wrong switch.
18 hours and many tired engineers later, we’re recovering from having lost our Chicago datacenter. In the takein that follows, we trace the root cause to a single network cable that’s mistakenly connected to the wrong switch.
Hi, my name is Alex, and I lead the Core Services group at Outbrain. Our group owns everything from the floor that hosts Outbrain’s servers, to the delivery pipelines that ship Outbrain’s code. If you’re here, you’ve likely heard of Outbrain. You probably know that we’re the world’s leading Discovery platform, and that you’ll find us installed on publisher sites like CNN, The Guardian, Time Inc and the Australian news.com, where we serve their readers with premium recommendations.
But it wasn’t always this way.
 You see, back when we started, life was simple: all you had to do was throw a bunch of Linux servers in a rack, plug them into a switch, write some code… and sell it. And that we did!
You see, back when we started, life was simple: all you had to do was throw a bunch of Linux servers in a rack, plug them into a switch, write some code… and sell it. And that we did!
But then, an amazing thing happened. The code that we wrote actually worked and customers started showing up. And they did the most spectacular and terrifying thing ever – they made us grow. One server rack turned into two and then three and four. And before we knew it, we had a whole bunch of racks, full of penguins plugged into switches. It wasn’t as simple as before, but it was manageable. Business was growing, and so were we.
Fast forward a few years.
We’re running quite a few racks across 2 datacenters. We’re not huge, but we’re not a tiny startup anymore. We have actual paying customers, and we have a service to keep up and running. Internally, we’re talking about things like scale, automation, and all that stuff. And we understand that the network is going to need some work. By now, we’ve reached the conclusion that managing a lot of switches is time-consuming, error-prone, and frankly, not all that interesting. We want to focus on other things, so we break the network challenge down to 2 main topics:
Management and Availability.

Fortunately, management doesn’t look like a very big problem. Instead of managing each switch independently, we go for a something called “a stack”. In essence, it turns 8 switches into one logical unit. At full density, it lets us treat 4 racks as a single logical switch. With 80 nodes per rack, that’s 320 nodes. Quite a bit of computes power!
Four of these setups – about 1200 nodes.
Across two datacenters? 2400 nodes. Easily 10x our size.

Now that’s very impressive, but what if something goes wrong? What if one of these stacks fails? Well, if the whole thing goes down, we lose all 320 nodes. Sure, there’s built-in redundancy for the stack’s master, and losing a non-master switch is far less painful, but even then, 40 nodes going down because of one switch? That’s a lot.
So we give it some thought and come up with a simple solution. Instead of using one of these units in each rack, we’ll use two. Each node will have a connection to stack A, and another to stack B. If stack A fails, we’ll still be able to go through stack B, and vice versa. Perfect!
In order to pull that off, we have to make these two separate stacks, which are actually two separate networks, somehow connect. Our solution to that is to set up bonding on the server side, making its two separate network interfaces look like a single, logical one. On the stack side, we connect everything to one big, happy, shared backbone. With its own redundant setup, of course.
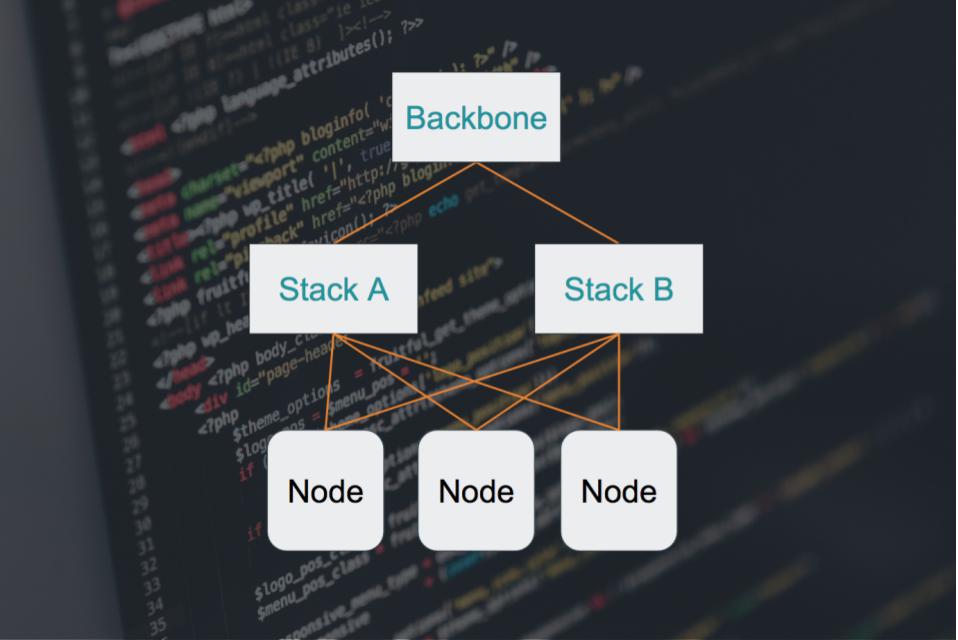
In case you’re still keeping track of the math, you might notice that we just doubled the number of stacks per datacenter. But we still gained simple management And high availability at 10x scale. All this without having to invest in expensive, proprietary management solutions. Or even having to scale the team.
And so, it is decided. We build our glorious, stack-based topology. And the land has peace for 40 years. Or… months.
Fast forward 40 months.
We’re running quite a few racks across 3 datacenters. We’re serving customers like CNN, The Guardian, Time Inc and the Australian news.com. We reach over 500 million people worldwide, serving 250 billion recommendations a month.
We’re using Chef to automate our servers, with over 300 cookbooks and 1000 roles.
We’re practicing Continuous Delivery, with over 150 releases to production a day.
We’re managing petabytes of data in Hadoop, Elasticsearch, Mysql, Cassandra.
We’re generating over 6 million metrics every minute, have thousands of alerts and dozens of dashboards.
Infrastructure as Code is our religion. And as for our glorious network setup? it’s completely, fully, 100% … manual.
No, really. It’s the darkest, scariest part of our infrastructure.

I mean hey, don’t get me wrong, it’s working, it’s allowed us to scale to many thousands of nodes. But every change in the switches is risky because it’s done using the infamous “config management” called “copy-paste”.
The switching software stack and protocols are proprietary, especially the secret sauce that glues the stacks together. Which makes debugging issues a tiring back-and-forth with support at best, or more often just a blind hit-and-miss. The lead time to setting up a new stack is measured in weeks, with risk of creating network loops and bringing a whole datacenter down. Remember August 13th, 2015? We do.
Again, don’t get me wrong, it’s working, it’s allowed us to scale to many thousands of nodes. And it’s not like we babysit the solution on daily basis. But it’s definitely not Infrastructure as Code. And there’s no way it’s going to scale us to the next 10x.
Fast forward to June 2016.
We’re still running across 3 data centers, thousands of nodes. CNN, The Guardian, Time Inc, the Australian news.com. 500 million users. 250 billion recommendations. You get it.
But something is different.
We’re just bringing up a new datacenter, replacing the oldest of the three. And in it, we’re rolling out a new network topology. It’s called a Clos Fabric, and it’s running BGP end-to-end. It’s based on a design created by Charles Clos for analog telephony switches, back in the 50’s. And on the somewhat more recent RFCs, authored by Facebook, that bring the concept to IP networks.

In this setup, each node is connected to 2 top-of-rack switches, called leaves. And each leaf is connected to a bunch of end-of-row switches, called spines. But there’s no bonding here and no backbone. Instead, what glues this network together, is that fact that everything in it is a router. And I do mean everything – every switch, every server. They publish their IP addresses over all of their interfaces, essentially telling their neighbors, “Hi, I’m here, and you can reach me through these paths.” And since their neighbors are routers as well, they propagate that information.
Thus a map of all possible paths to all possible destinations is constructed, hop-by-hop, and held by each router in the network. Which, as I mentioned, is everyone. But it gets even better.
We’ve already mentioned that each node is connected to two leaf switches. And that each leaf is connected to a bunch of spines switches. It’s also worth mentioning that they’re not just “connected”. They’re wired the exact same way. Which means, that any path between two points in the network is the exact same distance. And what THAT means is that we can rely on something called ECMP. Which, in plain English, means “just send the packets down any available path, they’re all the same anyway”. And ECMP opens up interesting options for high availability and load distribution.
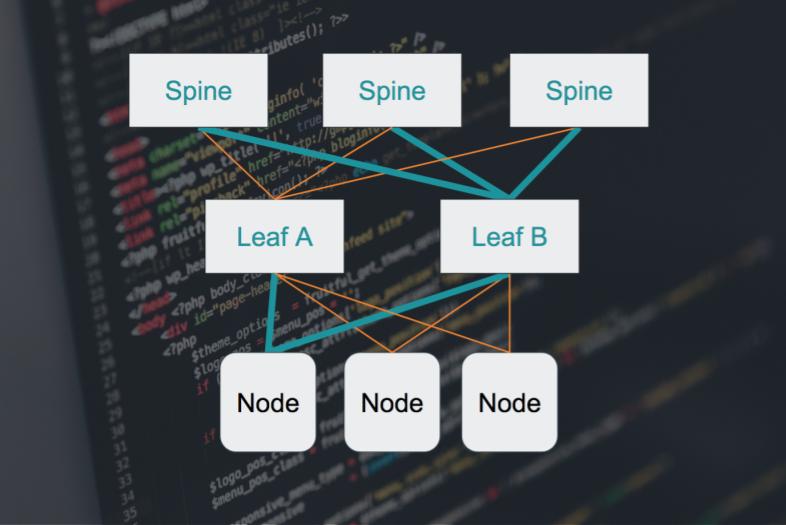
Let’s pause to consider some of the gains here:
First, this is a really simple setup. All the leaf switches are the same. And so are all of the spines. It doesn’t matter if you have one, two or thirty. And pretty much the same goes for cables. This greatly simplifies inventory, device and firmware management.
Second, it’s predictable. You know the exact amount of hops from any one node in the network to any other: It’s either two or four, no more, no less. Wiring is predictable as well. We know exactly what gets connected where, and what are the exact cable lengths, right from design phase. (spoiler alert:) We can even validate this in software.
Third, it’s dead easy to scale. When designing the fabric, you choose how many racks it’ll support, and at what oversubscription ratio. I’ll spare you the math and just say:
You want more bandwidth? Add more spines.
Support more racks? Go for spines with higher port density.
Finally, high availability is built into the solution. If a link goes down, BGP will make sure all routers are aware. And everything will still work the same way, because with our wiring scheme and ECMP, all paths are created equal. Take THAT evil bonding driver!
But it doesn’t end there. Scaling the pipes is only half the story. What about device management? The infamous copy-paste? Cable management? A single misconnected cable that could bring a whole datacenter down? What about those?
Glad you asked 🙂
After a long, thorough evaluation of multiple vendors, we chose Cumulus Networks as our switch Operating System vendor, and Dell as our switch hardware vendor. Much like you would with servers, by choosing Enterprise Redhat, Suse or Ubuntu. Or with mobile devices, by choosing Android. We chose a solution that decouples the switch OS from the hardware it’s running on. One that lets us select hardware from a list of certified vendors, like Dell, HP, Mellanox and others.
So now our switches run Cumulus Linux, allowing us use the very same tools that manage our fleet of servers, to now manage our fleet of switches. To apply the same open mindset in what was previously a closed, proprietary world.
In fact, when we designed the new datacenter, we wrote Chef cookbooks to automate provisioning and config. We wrote unit and integration tests using Chef’s toolchain and setup a CI pipeline for the code. We even simulated the entire datacenter, switches, servers and all, using Vagrant.
It worked so well, that bootstrapping the new datacenter took us just 5 days. Think about it:
the first time we ever saw a real Dell switch running Cumulus Linux was when we arrived on-site for the buildout. And yet, 99% of our code worked as expected. In 5 days, we were able to setup a LAN, VPN, server provisioning, DNS, LDAP and deal with some quirky BIOS configs. On the servers, mind you, not the switches.
We even hooked Cumulus’ built-in cabling validation to our Prometheus based monitoring system. So that right after we turned monitoring on, we got an alert. On one bad cable. Out of 3000.
Infrastructure as Code anyone?