Taming the bear (metal)

Picture by hansjurgen007 on Unsplash
Introduction
In this blog post, I am going to share with you the process behind Namaste – an automated tool we built, in order to manage our bare metal machine requests, as part of our BMaaS approach (that’s Bare Metal as a Service).
Who are we?
Before we dive into the new tool we built, let me introduce our team.
We are a team of 4 DevOps engineers based in Israel, managing an on premise environment of 7000 bare metal servers across 3 Data Centers in the US.
But there is a little bit more to it. When we say 7000 servers, it includes:
- about 20 different server models
- more than 100 different disk models
- …memory sticks
- …CPUs
- …raid cards
- ..NICs
- …PSUs
- …and a combination of all of the above
So there are a lot of hardware configuration options and a lot of reusing of the servers.
Since we are located in Israel and our Data Centers are located in the US, in each Data Center, there is a support team available 24/7 to handle everything on the physical side. They take the role of our “Remote Hands and Eyes” with any onsite related work. I will address them as “Remote Hands” in this blog post.
What we do?
We divide our work into 3 main types of tasks:
Planned changes – Our planned changes are managed in Jira and are mainly hardware related tickets opened by our customers – mostly engineers in the Cloud Platform group. We usually divide these tickets into 3 types of tasks:
- hardware upgrades
- service requests
- machine requests (which we’ll discuss in more details later)
These can be upgrading the resources of a server, working on a suspected hardware issue or building a new cluster altogether.
Unplanned changes – Everything which has to be done Now. During working hours it can be a task managed in Jira as a blocking/critical ticket. During off hours it can be a PagerDuty alert.
Internal projects – Projects which our team initiates and decides to manage. These are usually the tasks which our users don’t know or really care about, but those tasks are more interesting and make our users’ lives and our lives much better. In essence, our internal projects prevent unplanned changes and make the planned changes easier to perform. The new tool I’ll discuss falls under this category.
If you’d like to learn more about who we are and how we do things, I strongly encourage you to check out this great blog post by my colleague, Adib Daw.
The challenge
Looking back, a year ago our tasks were distributed like this:
Planned changes – 75%
Unplanned changes – 15%
Internal projects – 10%
This means 90% of the work was manual labor and 10% were projects geared towards automation. The meaning was both relatively slow delivery, much room for human errors and frustration due to the highly repetitive nature of most of the work. Simply put, it just didn’t scale.
Our solution to this problem was to formulate a vision, and present it to our customers to get their buyin. Our customers agreed to take a hit on the delivery times of their requests, so we could focus on the “internal projects” category, with the intention of investing in automation, and thus the velocity and robustness of our execution.
We decided to push towards building as many automated processes as possible, in order to minimise the amount of time spent on planned changes and unplanned changes, since many of these tasks appeared to lend themselves quite well to automation.
The “before” picture
When we began our journey towards automation, the process of choosing the best suited servers for the machine request took us a lot of time.
It looked like this:

- Check available hardware and verify we have enough free servers to fulfill the request
- Choose the best suited hardware by carefully (and manually) ensuring hardware constraints are met (suitable server form factor, support for required number of drives, RAID adapter, etc)
- Reserve the servers in a temporary allocation pool so no one else will use them for something else as they’re being worked on
- Allocate the relevant parts in our inventory system
- Submit the target configuration into the Remote Hands management system we’d built, so that the onsite technician would have the required information for the task (server setup and required parts)
- Open a ticket with the relevant information (server locations, serial number, etc) to the onsite Remote Hands team, to begin work on the hardware configuration changes
All of this had to be done before any actual hands-on work on the hardware even started.
In addition, we also had to deal with failures in the flow:
- configuration mistakes
- hardware mismatches
- human errors
- faulty parts
The “after” picture
The process we had worked, but it took a lot of time, sometimes as much as hours per request, depending on how many servers were requested and what changes were needed to their config.
While we had a set of tools that helped bring us to this stage – much improved over the previous process we had, which could take days for large requests – it would keep us afloat but still required manual labor which seemed entirely unnecessary.
Our vision for this process was to simplify it, to look as follows:

- Submit a request for the final server config, detailing number of servers per datacenter and their final spec
- Drink coffee while Namaste handles everything in the background, including opening a ticket for Remote Hands
- Get notified that the request was fulfilled
This simplified process would have code deal with the metadata matching, allocation and reservation, and leave us to handle fulfilment rejects, where human intervention is really necessary.
Behind the scenes
The flow of matching machines per a machine request:
- Accept user input – We enter server requirements such as quantity, location and spec
- Perform machine matching – An engine we built returns all the servers matching the requirements, some of which may be a partial match (missing a drive, less RAM, etc)
- Prioritise – Prioritise from the matched server list, based on:
- Rack awareness
- Server form factor
- Drive form factor
- Number of cores closest to requested spec
- Hardware changes required to bring machines to the requested spec
- Reserve machines – Reserve the prioritised servers in a temporary pool to avoid double allocation
- Perform parts matching – Decide which parts to use to bring the reserved servers to the requested spec, wherever needed
- Reserve parts – Reserve the selected parts in our inventory to avoid double allocation
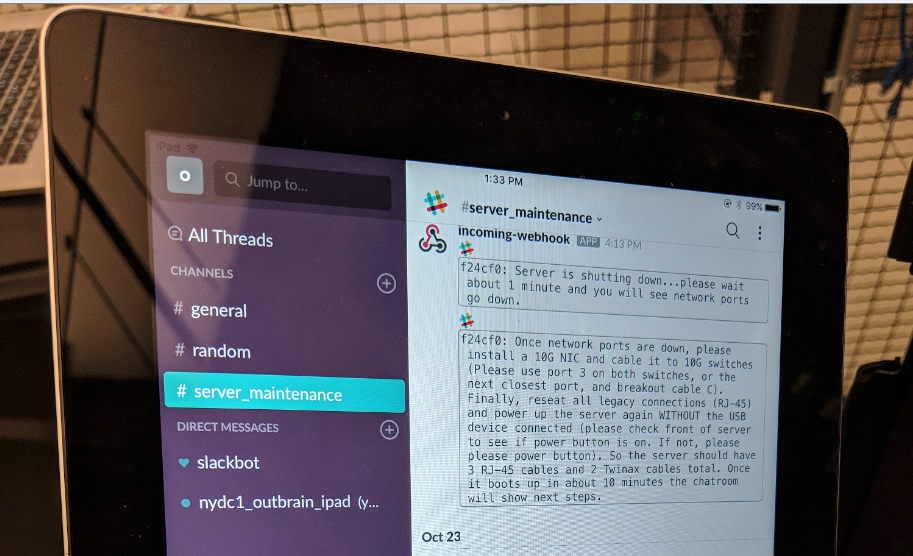
- Set machines to target spec – Mark the servers with the needed changes, so when the onsite support team begins working on fulfilling the work order, they will connect an iPad to each server which will tell them what changes need to be done.
- Open a ticket – Open a ticket with all the relevant information to the onsite support team for fulfilment.
Return on investment
The most obvious gain in developing this mechanism is time saving. With the steps of matching hardware and reserving parts being the main points of friction that were removed. Time saving also shortens the wait for hardware request fulfillment, so both the team and the customers win.
Automated matching also reduces human errors, which has impact on time saving as well as on customer experience. In addition, it further allows us to use the best suitable hardware, which improves efficiency by assigning the best matching resource to fulfill the request. Simply put, we no longer assign the “first matching” or “random” servers. Instead, we select the “most fitting” ones, as the matching algorithm is now explicit and repeatable.
A “side effect” of the improved matching process is that a whole class of issues is avoided completely. Those are issues around server <-> part incompatibility, maximum server capacity and generally everything Remote Hands might come across after the request had already been dispatched to them. These kinds of issues are the most expensive time-wise, as they require human to human communication across different time zones. We knew this would help, but the actual impact was astounding.
Finally, the user experience dramatically improved with the introduction of this system:
- Users request hardware get their requests fulfilled quicker
- Remote Hands come across less issues in the field
- Our team deals with much fewer rejects and manual labor
As you can see, there are 3 types of customers here, and all come out on top.
A short summary
A year ago we embarked on a journey to build our BMaaS solution, where Namaste is just one part of the full picture. While this is still a work in progress and we expect it to continue evolving indefinitely, now is a good opportunity to look back on where we started, specifically on what drove us down this path.
At the beginning of this post, I mentioned what our work distribution looked like before we decided to change things around. To remind you, it was something along:
Planned changes – 75%
Unplanned changes – 15%
Internal projects – 10%
A year into the process, the nature of our work has changed dramatically, and the work distribution is now more along:
Planned changes – 15%
Unplanned changes – <0.1%
Internal projects – 85%
It’s important to note that the actual volume of changes hasn’t decreased. In fact, we now handle more hardware fulfillment requests than ever before. But the actual mindful attention these changes require from us has dropped significantly. Instead, we focus mostly on building the system that gets the work done for all of us, shifting us from “moving hardware” to writing software.
What’s next
- APIs – by making our BMaaS platform’s APIs open to our users, we expect new and unforeseen use cases to surface, where our users build their own solutions on top of the platform
- Web UI – much of what we do is currently accessible via command-line tools. While this works, a web UI could improve the user experience even further and allow building various views which the system doesn’t support as of yet
- Events & notifications – our team still serves as a communication pipeline in various parts of the process, as we’re validating different ideas and ensuring everything works as expected. We plan to introduce events and notifications that would remove us entirely from the flow and allow users to act upon certain events, in-person or via their own code
- Coffee – maybe move to some decaf. Or tea.