"Outbrain connects businesses with engaged audiences, using AI prediction technology to drive better marketing and publisher results."
David Kostman Co-CEO




"Outbrain connects businesses with engaged audiences, using AI prediction technology to drive better marketing and publisher results."
David Kostman Co-CEO
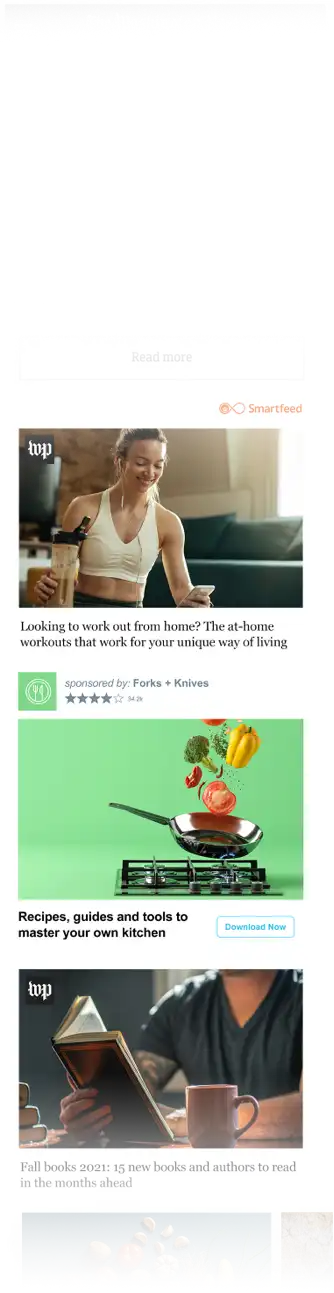
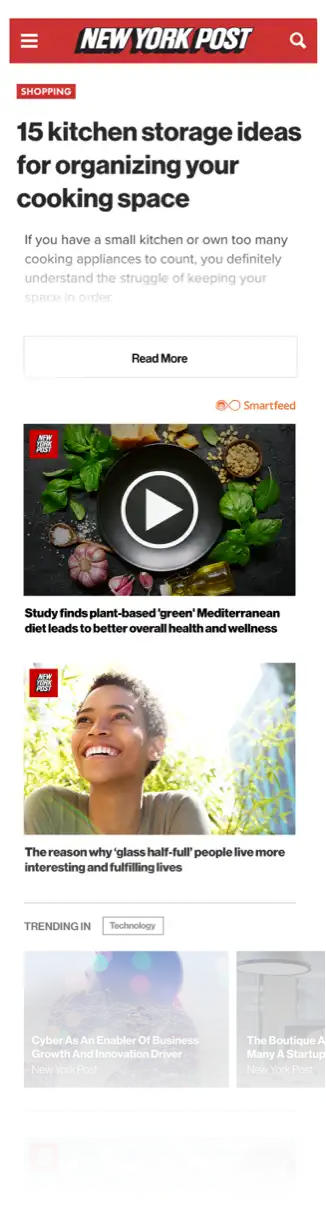
Deliver more impactful branding in premium, viewable environments that drive greater attention.
Drive greater ROAS with efficient bidding tools designed to maximize your results, at scale.
Benefit from 17+ years of consumer interest and intent data, fueling unrivaled outcome prediction.
Context-Powered Video, High-Impact Display, or seamless Native to drive your desired result.
 -45% Cost Per Visit+27% ROAS68% Video Completion+50% Revenue Growth
-45% Cost Per Visit+27% ROAS68% Video Completion+50% Revenue GrowthMany more worldwide
Many more worldwide
Many more worldwide

Dependable revenue delivered by direct demand suite across branding and performance budgets, optimized by award-winning Smartlogic technology.
Publisher suite of tools powering deeper audience engagement, recirculation, and loyalty.
Maximized total revenue across your site with tools for ad sales, eCommerce, and more.
Context-first approach, optimizing relevance and impact while respecting end users.
Recognized Across the Industry







Brand Safety & Fraud

Attention Measurement
Vast and vpaid standards

Avocate for quality original digital CONTENT
Autorité de Régulation Professionnelle de la Publicité

General data protection regulation

Certified video publishing partner

Tag certified
