Yet another Hadoop migration – but from the human perspective

This blog is about our last Hadoop migration but from a different angle, instead of describing the technical aspects of it (don’t worry, I will go over it in addition) I will be more focusing on the human perspective of it, how and why we took the decision to go from (attention, spoiler alert!!!) commercial to community solution.
Background
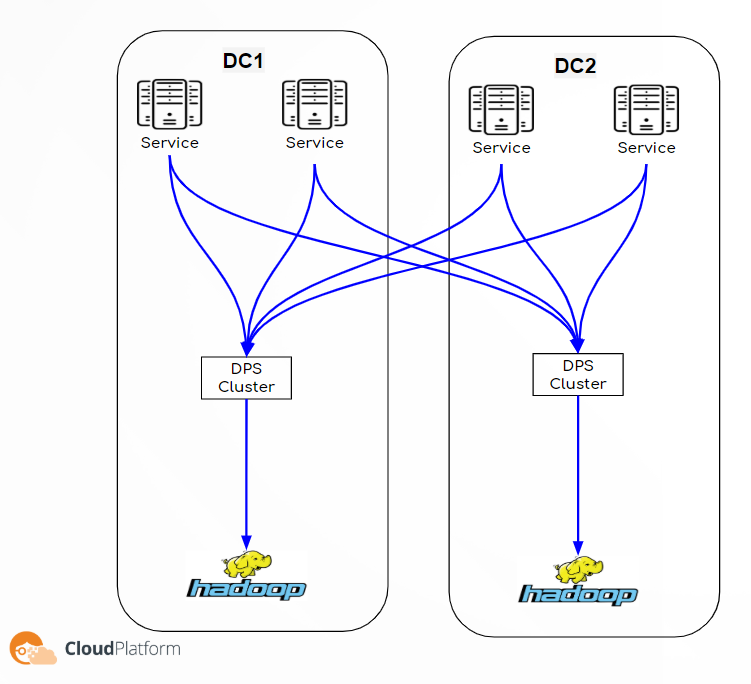
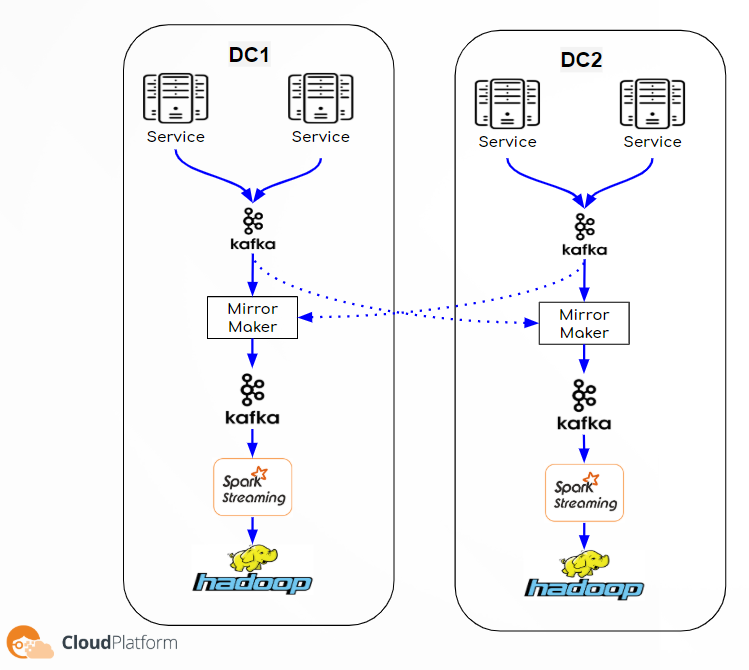
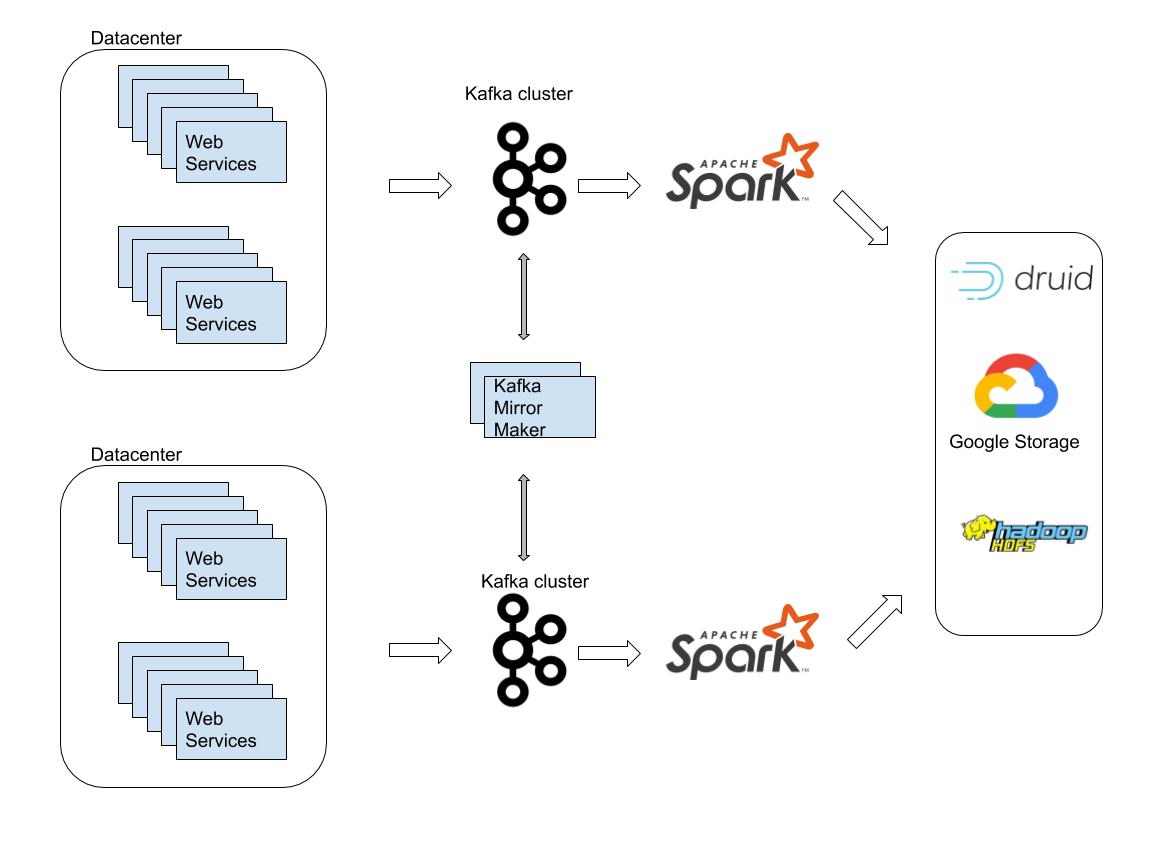
But first some context, Outbrain is the world’s leading content discovery platform. We serve over 400 billion content recommendations every month, to over 1 billion users across the world. In order to support such a large scale, we have a backend system built of thousands of micro services running inside Kubernetes containers spread over more than 7000 physical machines in 3 data centers and in public clouds (GCP & AWS). In order that the recommendations we supply will be valuable to our readers we invest in personalization as much as possible. To achieve this goal we have lots of machine learning algorithms that run in the background on top of the Hadoop ecosystem which makes it a very critical system for our business, we have 2 flavors of Hadoop clusters:
- Online – we have 2 clusters in full DR mode running on bare metal machines, they are used for online serving activities.
- Research – we have several clusters (per group and usage) running in GCP, they are used for research and offline activities.
Every day each cluster gets over 50TB of new data and there are over 10K job executions.
The Trigger
Few years ago we migrated our online Hadoop clusters to use the MapR commercial solution (you can read more about this in the Migrating Elephants blog), it had lots of improvements and we enjoyed the support we got. But a few years later, our Hadoop usage increased dramatically which made us very professional in supporting this system, we improved our knowledge and we could handle things on our own instead of depending on external resources for solving issues (which is one of the benefits when using a commercial solution). So, a few months before the license renewal we wanted to get a decision for what is the best way for us to proceed with this system.
We knew that it can take us some time until we will come up with new solution in production, we needed to make sure that the current system will continue to operate so we did the following actions in order to mitigate the time factor:
- MapR have also a community version, we mapped the differences between it and the commercial version, there are few but the main ones that we had to solve were:
- No HA solution (for the CLDB, the main management service) – for that we implemented our own custom solution
- Support only single NFS endpoint – some of our use cases copy huge amount of data from the Hadoop into a separated DB so we needed a scalable solution, we ended up with a internal FUSE implementation
- Since we had 2 clusters in DR mode, we were able to test and run the community version in parallel to the commercial version
- Just for case, we made sure that we could extend the license for only several months instead of 3 years commitment
Those actions enabled us to make the right decision without any pressure, we made sure that we will be able to run the system with the community version until we will have the new solution in place.
The Alternatives
We came up with those alternatives:
- Stay with the MapR commercial version – we didn’t want to stay with the community version (don’t have big users adoption and support).
- Migrate to Cloudera commercial version
- Migrate to Cloudera community version – this option was dropped immediately since the amount of nodes we had (>100) exceeded the limitation of using the community version
- Migrate to Apache Hadoop community solution
- Migrate to Google Cloud – the same we did with our research cluster
In order to be able to compare between those alternatives, we first defined the measurements that will help up to determine the chosen alternative, we summarized all in the following table:
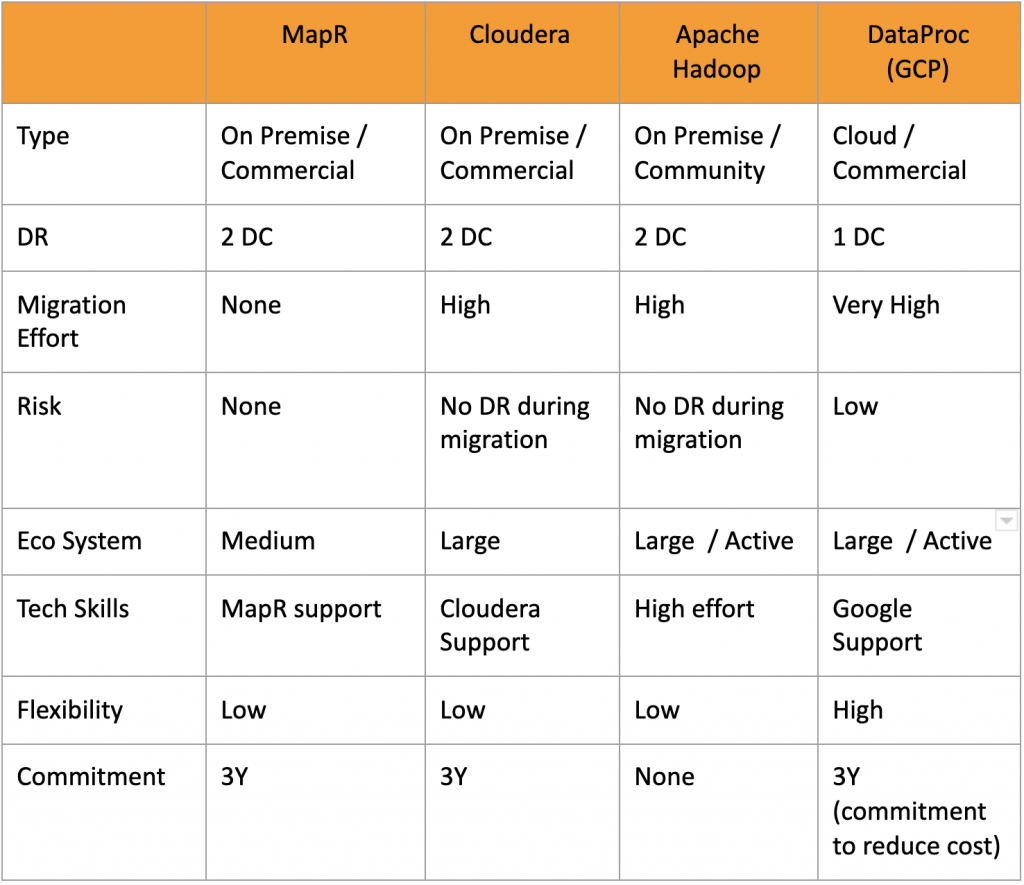
There were other measurements like cost and required additional headcount, but they were not factors in our decision.
The Decision
After the successful migration we had with the research cluster to GCP (you can read about this in the Hadoop Research Journey blog series), lots of us thought that once we will need to migrate the online clusters, they will be migrated also to GCP. But like in real life, you need to handle each case by its own characteristics. I have 4 children and I wish that there was a single way to rule them all, but the reality is that each one requires a different approach and a different attitude. The same goes with our Hadoop clusters, each one has its own characteristics so each one has different requirements and needs, they differ by their usage so what is good for one is not necessarily good for the other. Due to the nature of the online clusters (lots of compute, less storage) we realized that we will not be able to benefit from the cloud features (elasticity and compute-storage separation) like we had with the research cluster.
Like said before, case-by-case, we needed another solution for our online clusters. Following this conclusion it was clear that the chosen solution will be from one of the bare metal alternatives. This left us to choose between the community and the commercial versions, we compared the pros and cons of each option but the main question was: do we want to pay for a license or to invest the money in training people and have better internal skills?
We figured out that the professional level we will have will have the best impact, it will be a win-win situation, our users (the engineering teams) will get better service and we will invest in our people. Following the post’s title, we took the dissection from the human perspective. Having said that, it was clear that the winning alternative was the Apache Hadoop Community.
The Migration (in short)
The migration needed to be done while the system itself continued to operate as a production system, this meant that we needed to continue to give the same service to the users while they will not be affected. As we have 2 clusters in separated DCs, so we did it one cluster at a time, in each it was done in a rolling manner, we started with a small Apache cluster and in several cycles we managed to move the workload from the MapR cluster into it.
Data migration
- New data – we started to ingest the new data into the cluster, it was done by integrate the Apache cluster with our data delivery pipeline
- Historical data – most of the workload needs some historical data for their processing, as the migration was in cycles, we copied only the data that was required for each cycle
Workload migration
We repeated the following steps until we managed to migrate the entire workload:
- Moved some of the jobs from the MapR cluster to the Apache cluster
- Stopped the migrated jobs in the MapR cluster
- Moved machines from the MapR to the Apache cluster
The ability to perform those cycles was thanks to mapping we did, we defined the groups of jobs that can be moved together in one piece taking into consideration the dependencies between the jobs and the cluster capacity. The last cycle contained all the jobs that were tightly connected to each other and there was no possibility to be separated.
Of course there were lots of other technical details but they are a subject for a separate blog.
Achievements
The migration was a huge success, it was a full cooperation of all relevant engineering teams. After preparations that took us a few months, in no time (~1 month per cluster) we managed to complete it.
Now we can summarize what we achieved:
- The human factor – our people improved their technical skills and got more professional in supporting the Hadoop system
- We are using Open Source Software – there are lots of articles describing the benefits of using open source software which are: flexibility and agility, speed, cost effectiveness, attract better talents etc.
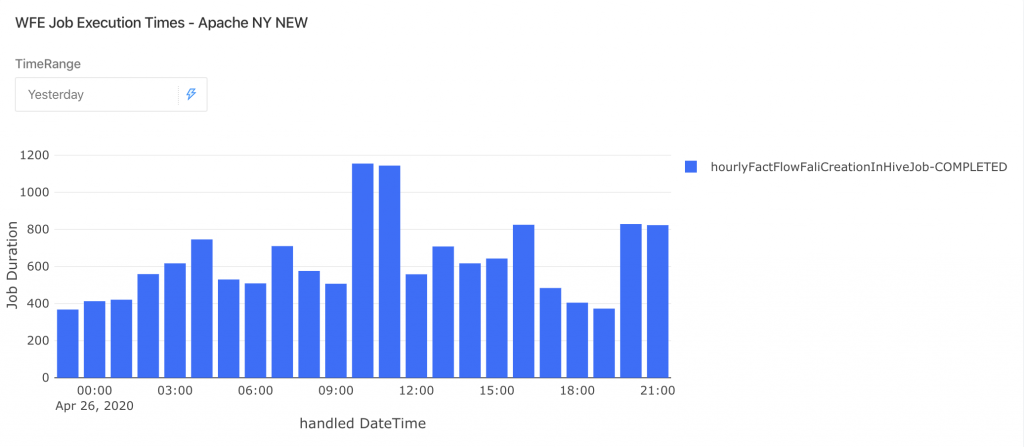
- Improved cluster performance – with the same amount of cores (actually with a little less), all jobs finish their processing at least 2 times faster. For example, in the below graphs you can see the process time of the hourlyFactFlowFaliCreationInHiveJob in the Apache vs. MapR
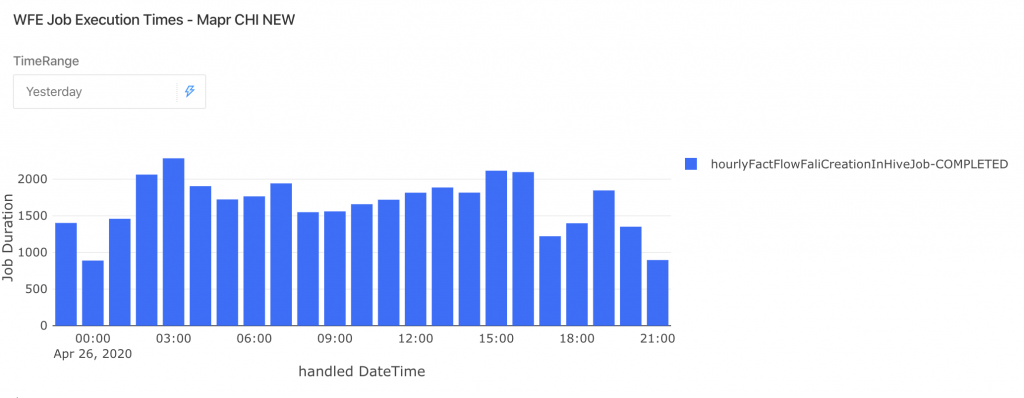
- Cleanup – as a preparation for the migration we mapped the storage and workloads that will be migrated, this enabled us to perform cleanups where possible
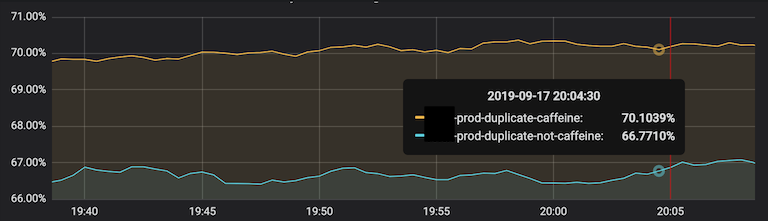
- Storage – we were able to delete more than 700TB which reduced the cluster capacity from 73% to 49%, you can see the impact in the graph below
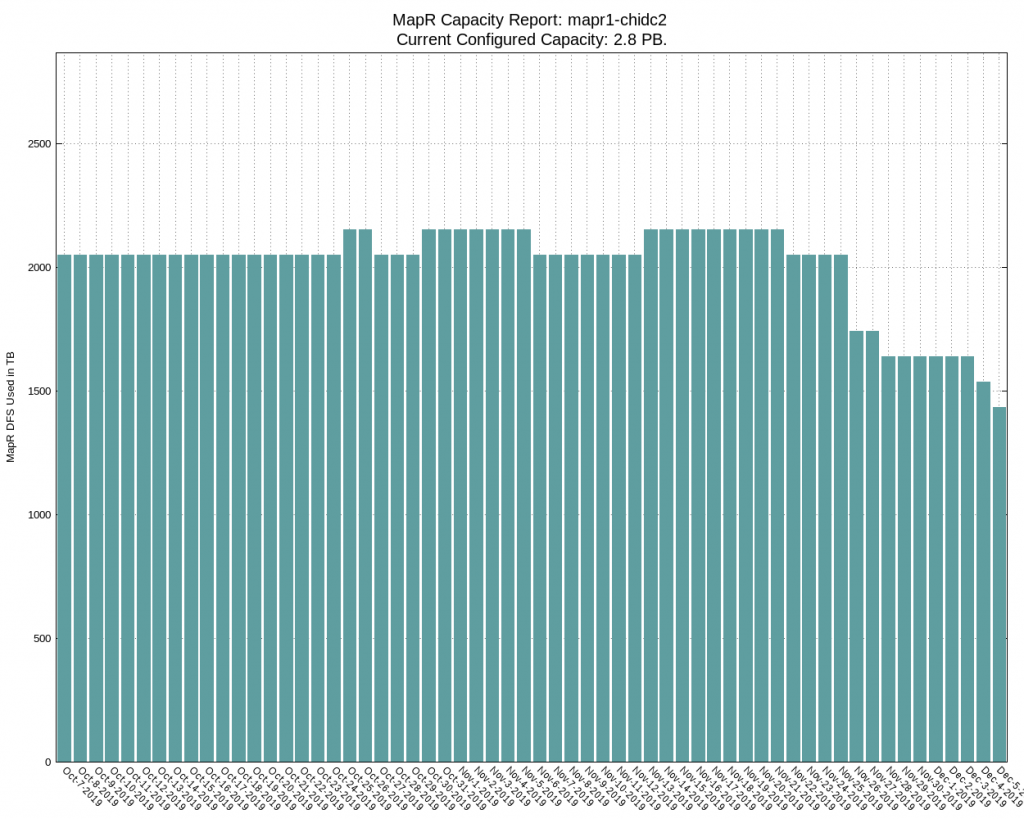
- Workloads – we disabled more than 800 jobs which was almost half of the total number (today we have ~950 jobs). In addition, we made some order with the jobs owners so instead of 19 ownership groups we now have only 16
- Technical debt – one of the advantages of moving to open source software is the ability to use the latest versions of all integrated packages and in addition to be able to integrate even more packages, this ability is sometimes missing when using a commercial solution. In our case we were able to:
- Upgraded our Spark jobs (version 2.3)
- Upgraded our SparkStreaming jobs (version 2.4)
- Implemented Presto as another service for supplying a high performance query engine that can combine few data sources in a single query.
Epilog
The decision to migrate one of our critical systems from commercial to community version was not an easy decision to make, it involved some amount of risk but according to the blog’s title, we did it from the human perspective, when you invest in the people you get the investment back in big time.
Taking such a brave decision requires strong leadership, by nature there are always few sceptical people that fear changes, especially from such a big change in such a critical system. We needed to be determined and express confidence in the people and in the process, all people must be committed and engaged to this decision.
To summarize things up, the migration was a big success from the human perspective and from the technical aspects, it was a team effort that we all are enjoying its outcome. And regarding the different solution per Hadoop cluster, like in real life, try to follow the rule of case-by-case.