
Intro
Kubernetes is the best thing since sliced bread. Everyone is talking about its internal parts, how to use it, best practices and the latest and greatest supporting tools for it.
This isn’t a story about how great Kubernetes is (yes, okay, it’s great). It’s about our journey into the realm of large scale deployments, and why we’re not using Kubernetes. Okay, we are, but we hide it.
This blog post was put together by Shahaf Sages, Dafna Frank and Alex Balk.
In the beginning
A long time ago in the early 2000s, in a startup far-far away, there was a lone Java developer. The developer had a mission. It was an ambitious mission, one that was not for the faint of heart. His mission was to write the most beautiful Java code ever written, and make some sweet startup money along the way.
Actually, this developer wasn’t alone. And frankly, his code wasn’t that good, but it worked, and he, and his fellow “lone Java developers” needed to get this code to production. And so they did, using the tools they knew best: copy & paste… but in the Linux variant, called “scp”. And the sweet startup money flowed. Or at least trickled a bit.
It’s good, but is it good enough?
This worked well for a while, but not very well or for very long. Fairly quickly, problems started showing up. Problems that needed more code to be written, uploaded and managed on production machines. Which too started to add up. Version control, which was so common in the process of writing code, was desperately needed in the process of deployment. And rollbacks, because the beautiful code was sometimes moody. And some way to keep tab of these (also moody) machines where the code was running. Because sometimes they had an annoying tendency to die or just stop responding.
And so it was decided by the great powers of infrastructure development that be. There will be no more “scp”ing, as it was declared to be manual and thus the root of all evil. Instead, a system shall be born – a deployment system, with artifact version control, build management, rollbacks, progress bars, a model to account for all machines and services, and access control to grant permissions to the lucky few who shall unleash their code onto production. And it was dubbed GluFeeder, for it was based on the Open Source Glu framework from LinkedIn which was state of the art at the time. And it was GOOD.
It works so well, why touch it?
Until, 8 years later, it wasn’t all that good anymore. But that took a long time, and everyone got used to it and it hid away many problems. So if it works don’t touch it, right?
Maybe not. Problems were abundant:
- The small (not so much) startup ran on physical machines, and each service had an entire machine for its own, which meant quite a bit of waste
- The small (not so much) startup was moving towards microservices because they’re cool and scalable and async and shiny, so said waste was about to get out of hand because there were now a lot of services
- The moody physical machines were still moody and whenever they decided they didn’t want to work anymore, all the services running on them just died in nasty, nasty ways
- The model for describing “what service runs where” was handled in one big yaml file and all the developers had their sticky fingers touching it directly, with no validation
- Adding more service instances was really really REALLY painful because the new physical machines that were ordered took a long, long time to arrive at the (not so small) startup’s datacenters
And so it was decided by the great powers of infrastructure development that be. There will be no more GluFeeding because it worked but wasn’t “10x scale”. Instead, a system shall be born – a deployment system, with:
- Support for containers, because the Java developers were making friends with JavaScript and Python and Go developers
- A per-service model stored in a real database with all the metadata goodness that describes how to build, run and operate micro, macro or mega services
- A resource management system, the best Open Source had to offer, to manage the moody server resources and ensure code was running even if servers went away – the almighty Kubernetes
- Orchestration of many, many resource managers (Kubernetes clusters), across many, many datacenters, or at least 3
- A well defined contract between the services and the environment they run in, so that everyone gets their metrics, logs, environment variables and properties in the format and flavor they prefer, without dealing with the gory, gruesome details
A poll was run and the people voted. The name that was chosen was Dyploma (DYnamic dePLOyment MAnagement system), which only shows that democracy doesn’t always work very well.
One small step for dev, one giant leap for devops
In the course of a year and a half, the infrastructure developers and the Java early adopter developers met every week to present, discuss and test what was being developed. A Python CLI was chosen as the initial interface for the system, as it was quick to develop and required little UX skills. Little by little the features were added, tweaked and tuned. And little by little confidence was built in the new system and the great Kubernetes beast which it controlled through the scriptures of the fabric8 java client. Until the Python CLI was no longer enough and a Vue.js Web UI was added instead.
Great care was taken in the design to ensure only metadata was kept within Dyploma, so as not to contaminate it with duplicate state of the Kubernetes beasts. And so Dyploma was lean on data and mostly just passed orders to Kubernetes, Prometheus, Consul, Jenkins, TeamCity, Bitbucket and anyone else it could boss around. The system would let the developer:
- Describe the service’s endpoints
- Provider special build parameters
- Set runtime information, such as environment, cluster, number of instances
- Build, deploy, scale up/down and disable with one click
- View what’s running, where, how much, why and who gave the order
- And just plain hide away all of the underlying systems details because the developers were lazy and spoiled and we LOVE them that way
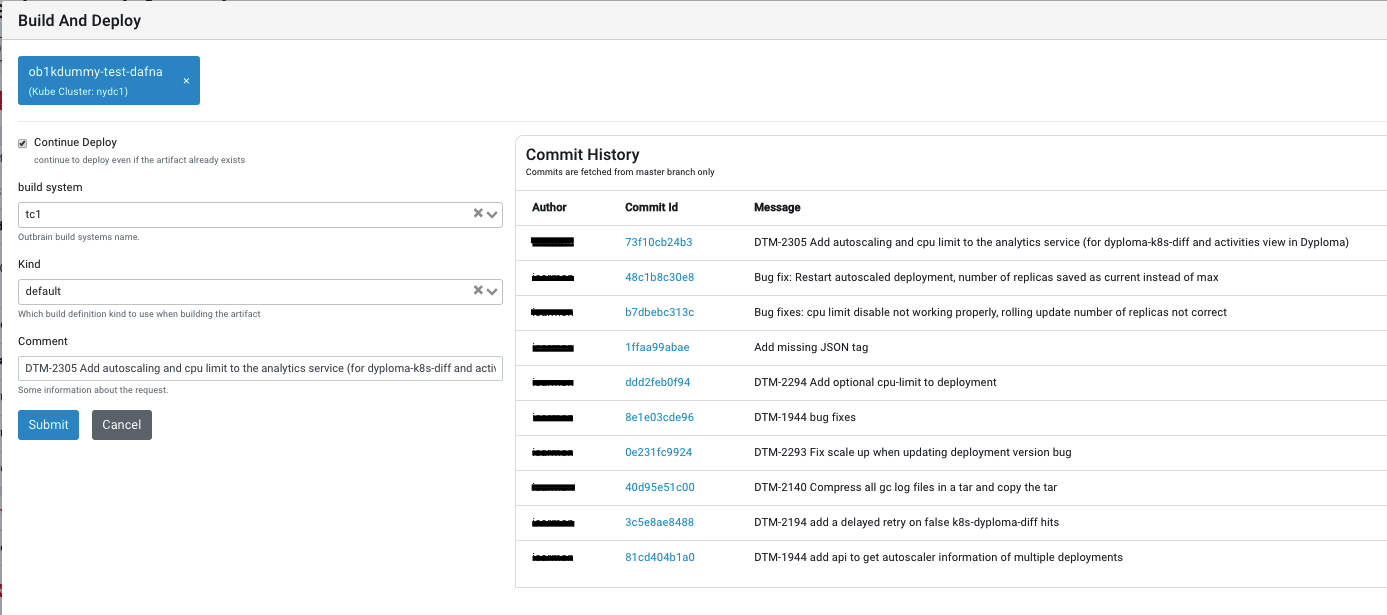
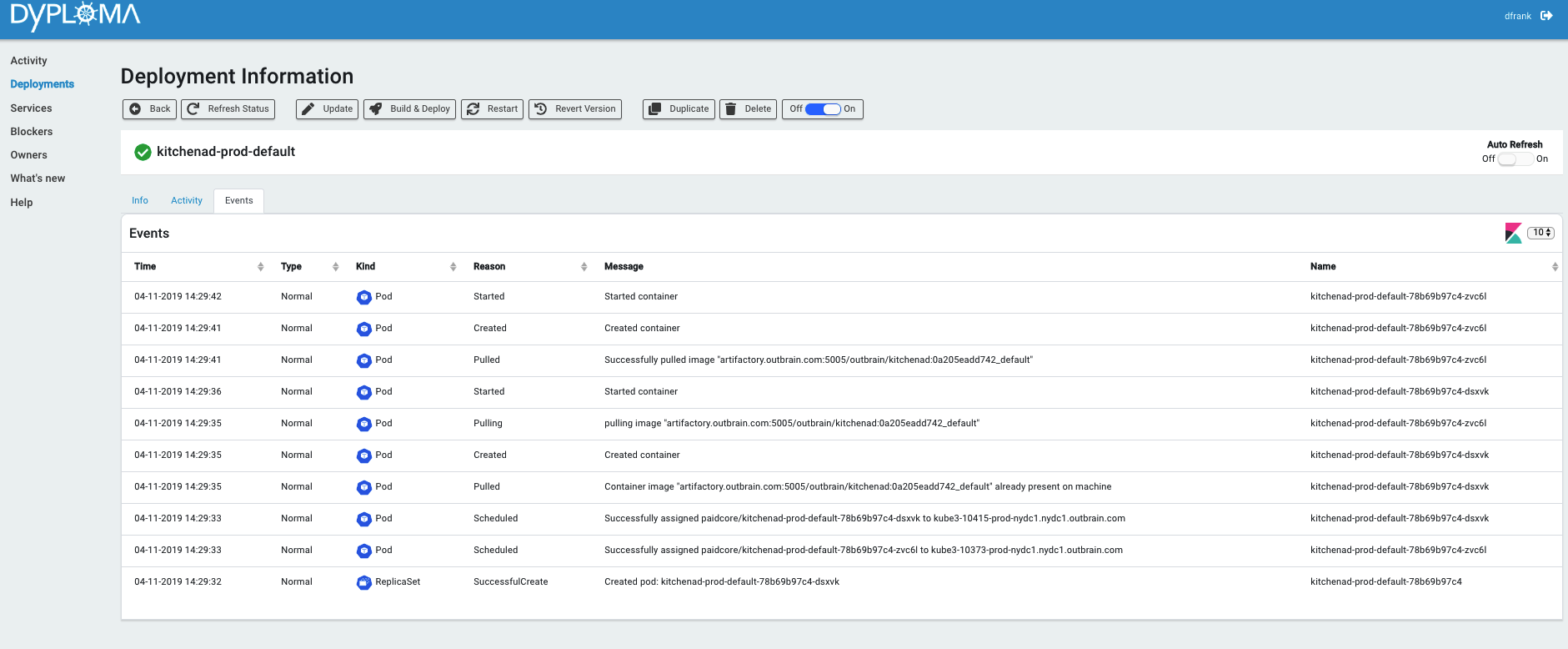

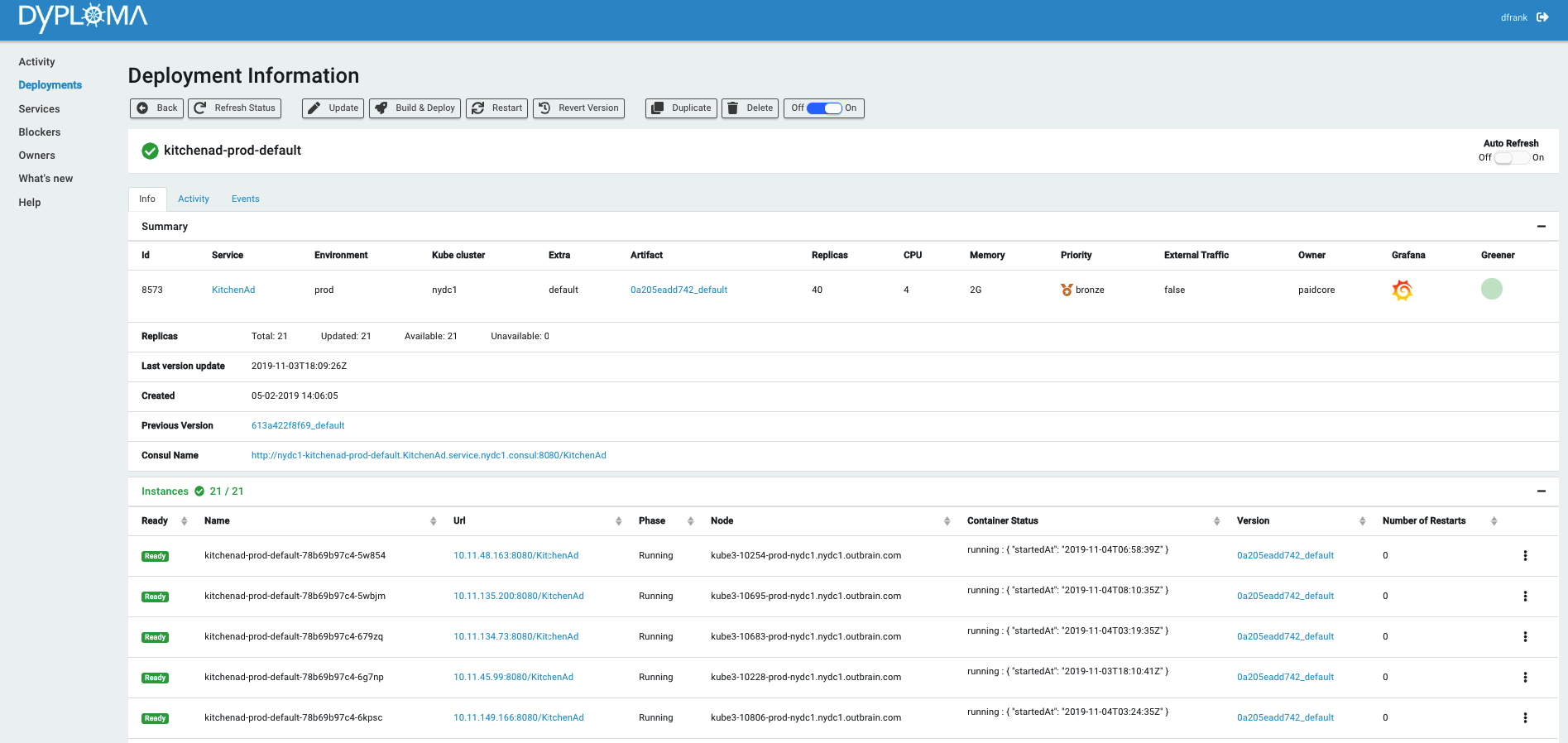
No, really, let’s unfold that last statement
The developers didn’t need to know anything about making the underlying infrastructure work. They just got it all for free. Gift wrapped with a nice web UI. Once they had their service defined, all they had to do was decide how much, which version and where, and pay the bill (okay, not yet, but it’s coming). There were no yaml files, no Helm charts, no configMaps or anyone called Jason. There was a single place to view the runtime status of a service, its history of changes, its logs, graphs and a single place to control it all, which even had batch operations but that’s just showing off.
And so simplicity was restored, velocity was increased, stability was a welcome side-effect and much cost was saved through better resource utilisation and reuse of aging moody machine hardware. And it was GOOD.
Until, one day, a lone Java developer had an idea.
“Why don’t we ditch Dyploma and use Kubernetes instead?”, he said. “I’ve read that it’s the best thing since sliced bread.” And the infrastructure developers just stared.
Show me the money
Every Kubernetes blog post that respects itself shows off some numbers and yaml files.
We have no yaml files to show you, but we do respect ourselves, so here are some numbers:
GluFeeder
Machines managed: 2000
Services running on the managed machines: 2500
Unique types of services: 150
Dyploma
Machines managed: 1600
Services running on the managed machines: 7500
Unique types of services: 400
Kubernetes deployments: 2300
EPILOGUE
Since you’ve read up to here, we’ll assume that you’re interested in getting some insights around building a deployment system (vs yet more Kubernetes tips & tricks), so we’ll give you some of our inputs:
- We wanted flexibility AND simplicity. This isn’t cheap. If you want developers to “just write code”, you’ll have to have other developers “just write infra”.
- Deployment systems are built for users. Bring the users onboard for the ride if you’re building one.
- Use the terminology of the system you’re relying on. If it’s called a pod, call it a pod. Don’t call it a FLDSMDFR. We called a “deployment” a “service”. Don’t.
- Kubernetes is complicated. So is your runtime context (at least when you’re big). The challenge is in using the former to contain the latter, while simplifying it for the users. This means that the user should be able to say the absolute minimum and get sane defaults, but also be able to override everything in the runtime without having to speak any Kubernetes. Simple, right?
- Protect yourself. People will make mistakes. They will put the SVN version number in the replicas field. And you will cry.
Looking forward, this is what we’re working on these days:
- Horizontal autoscaling. Because after you’re done migrating, you start optimising. And you want it simple enough for devs to “click here”.
- Deployment A/B testing. All the levers are there, but you have to build them into a usable tool.
- Requests, limits and “let me set that for you”. Because they don’t necessarily mean what you think they mean.
- Jobs. Because crons are running wild and it doesn’t hurt us now, but only because we’re not looking.
- Exposing cost to owners. Because nothing is free, not even your own bare metal.
- Open Source. Because the world needs this.