Coding Game Story Two – How can Minions be used as a strategy and not just as a cartoon
This is part two of the Outbrain Haggling Game blog series. For the full description of the game we highly recommend you read the first part here.
When we heard about the game we were very excited. It’s fun to take a break from everyday work every once in a while to create something new and cool. Additionally, these games are a great opportunity to get to know coworkers we don’t get to interact with on a day to day basis. Moreover, the competitive nature of the haggling game was a huge draw to us – we love to win!
Before we describe our strategy and the implementation details, we want to reiterate the rules of the Haggling Game:
The Rules
The game is played by two players who negotiate the division of a group of items between them. The goal of each player is to maximise their score.
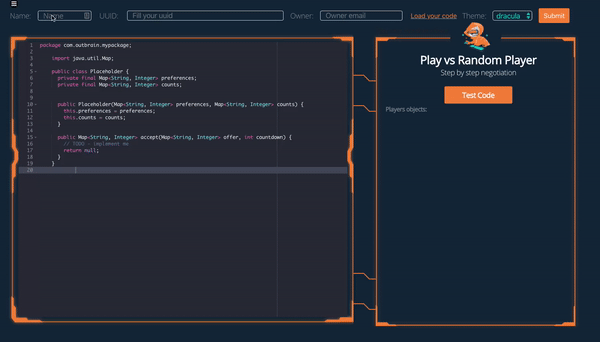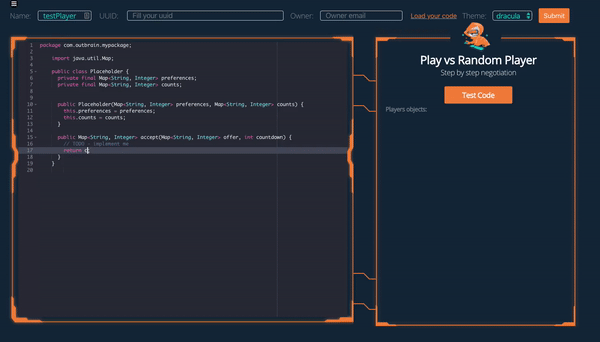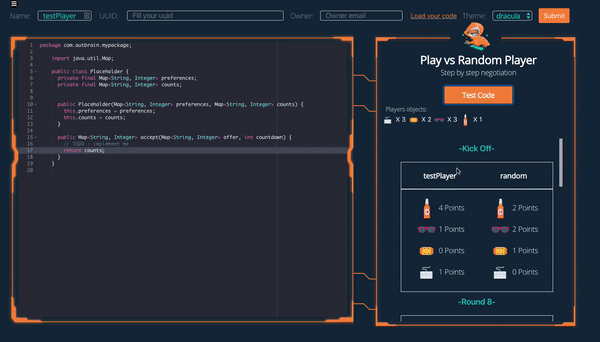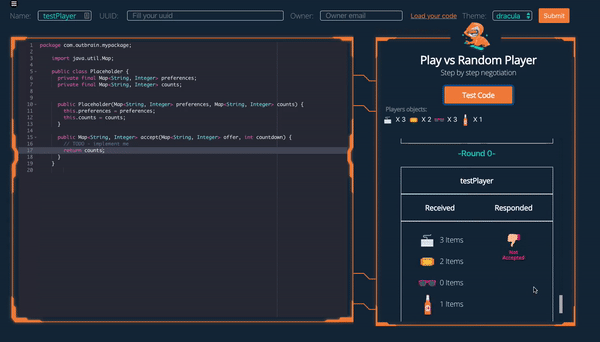
At the start of the game a set of ‘items’ is placed on the table (for example, a pair of sunglasses, two cups and a pencil). The players must agree on how to divide these items between them. The items are worth a different amount to each of the players, and the players know only their own preferences, and have no idea of the opponent’s. The total worth of all objects on the table is the same for both players.
The game consists of 9 rounds. In each round one of the players receives an offer of how to split the items and decides whether to accept it or return a counteroffer. If after 9 rounds neither player has accepted any offer the game ends with both players receiving 0. If at any point an offer is accepted each player receives the amount that their portion of the goods is worth to them.
Strategy – General Overview
Technical Strategy
We implemented a collaborative strategy, using two types of players:
- The “Overlord”, our winning player
- The “Minions”, helper bots whose job was to give points to the Overlord while blocking other players.
The Overlord and Minions recognize each other using a triple handshake protocol, based on mathematical calculations of the game parameters. Whenever a handshake completes successfully the Overlord requests the entire pot, while the Minion accepts the offer. In case the Overlord sees an unsuccessful handshake it moves to a competitive strategy and tries to claim the highest possible rewards using a player-vs-competitor bargaining strategy. Similarly, when a Minion realises that its opponent isn’t the Overlord it requests the entire pot in every round until the end of the game. This effectively blocks the opponent from receiving any points in this game.
Social Engineering
Beyond the technical strategy, we also employed a sort of “social engineering” : we hid the strength of the Overlord by ensuring that for the majority of the two-week development period the Overlord went no higher than third place. Given the amount of hacking going on during the game we wanted to make sure we didn’t draw undue attention, or become a major target to beat. We did this by populating the game with “sleeper cells” — players under our control running basic strategies ready to turn into minions at the right moment.
We waited until the last couple of hours of the game to start converting the minions. During the final hour, the Overlord shot to first place, outpacing the competitors by a huge margin. The strength of the technical strategy is evident by our spectacular win. However, the social engineering aspect is not to be diminished. In the last half hour of the game, we saw an attempt to hack our code in order to beat the Overlord. Our sneaky strategy did not leave enough time for the hacker to bring about our downfall.
Strategy – The Protocol
As we described, our protocol employs a triple handshake between the Overlord and a Minion. The roles of the Overlord and the Minion in the handshake are asymmetric.
The Overload:
- Never initiates the handshake
- Keeps the handshake state between rounds (Is the opponent possibly a Minion?)
- If at any round the handshake fails, falls back to play the “competitive strategy”
- If the opponent is believed to be a minion, demands all items
The Minions:
- Always initiates a handshake in the first round
- Keeps the handshake state between rounds (is the opponent possibly the Overlord?)
- If at any round the handshake fails, blocks the opponent from getting any points by demanding all items.
- If the opponent is believed to be an Overlord – the handshake is successful and the opponent requested the entire pot – accept the offer
Here we present the protocol flow and the code for the Overlord and Minion
For the remainder of this post “Counts” refers to the set of items that are on the table for this game.
Overlord Protocol:
We can see that the Overlord uses both the saved state and the received offer to determine whether this is a valid phase of the handshake..

This is a snippet of the Overlord’s code:
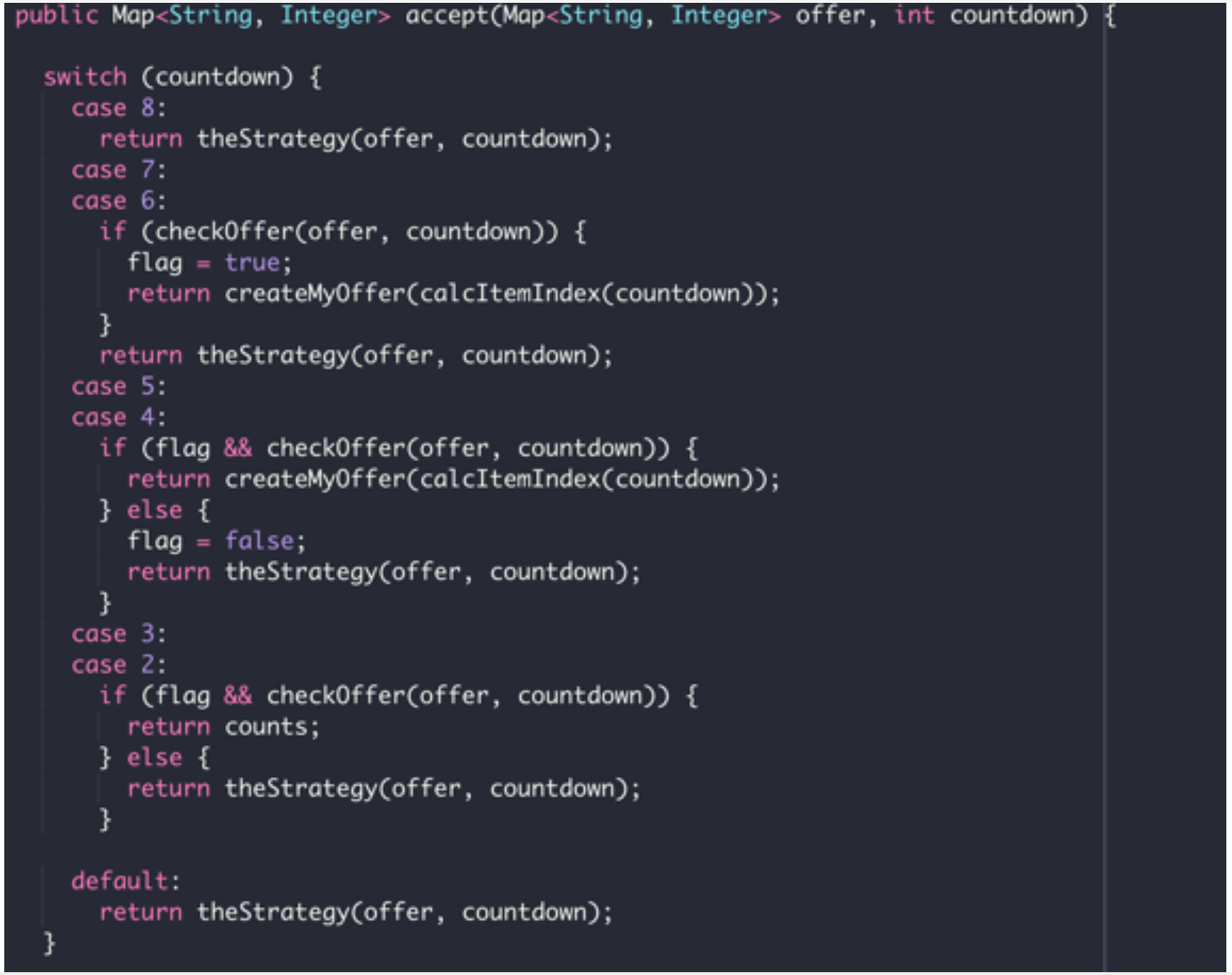
We can see that when the Overlord is the starting player it always plays the competitive strategy, and does not initiate a handshake. The Overlord checks the offers it receives to decide whether a handshake is ongoing. If at any point in the game the Overlord decides that the opponent is not a Minion it switches to the competitive strategy.
Minion Protocol:
The flow of a Minion playing against the Overlord
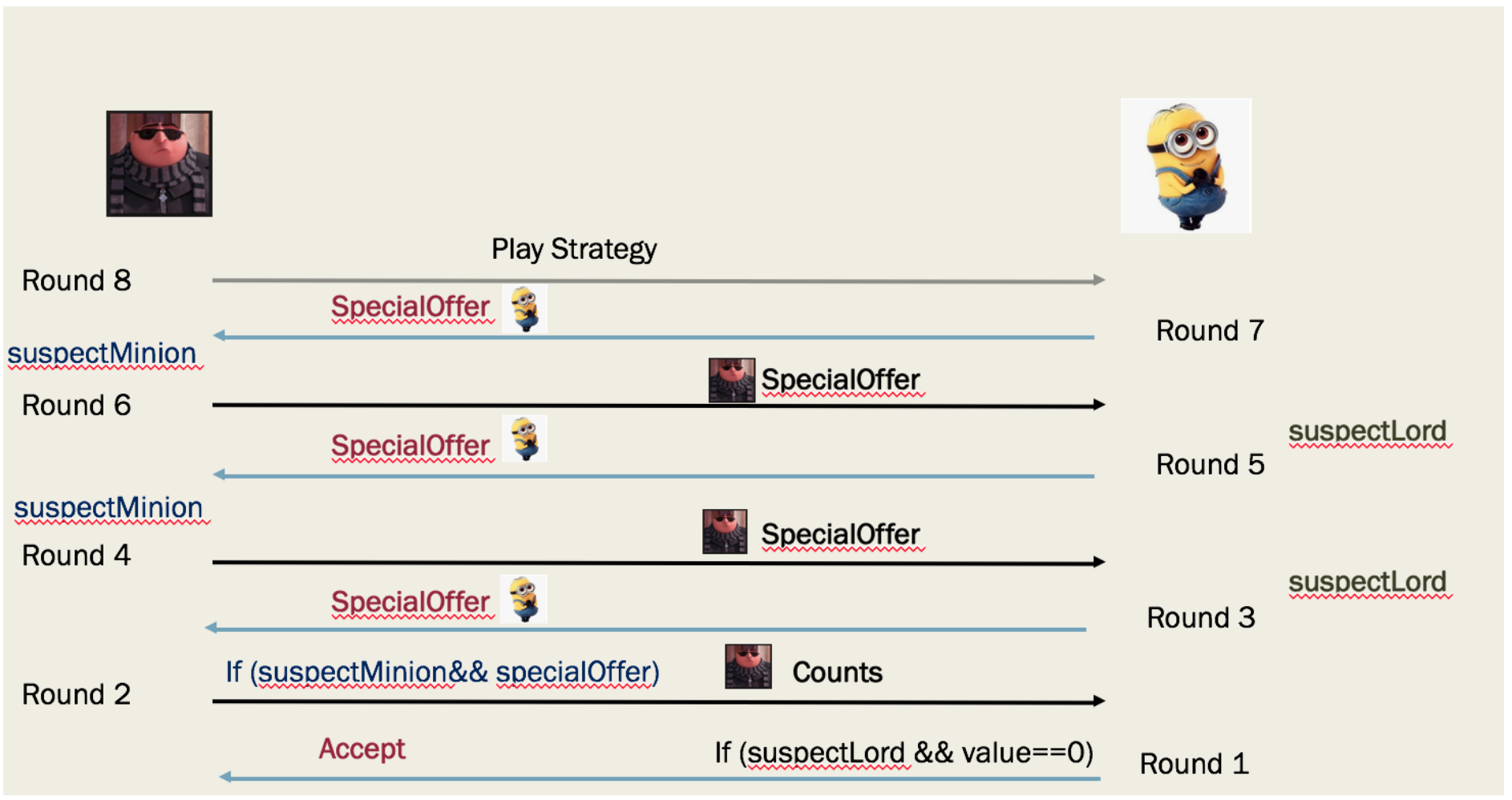
The flow of a Minion playing against a competitor:

This is a snippet of the Minion’s code:
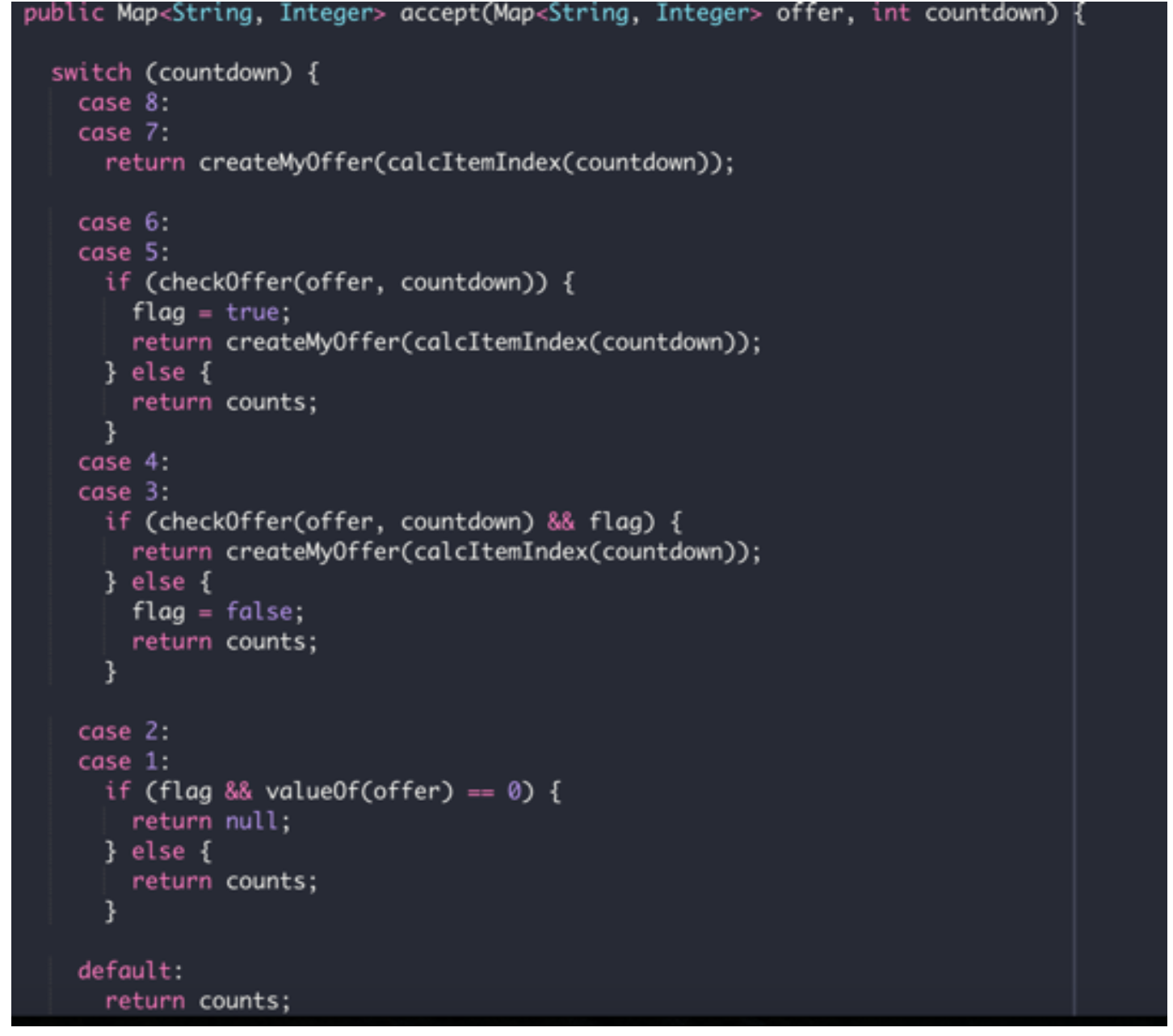
We can see that the Minion always initiates a handshake on its first offer, regardless of what it received. At any point in the game, if the Minion decides that the opponent is not the Overlord, it switches to a blocking strategy.
Protocol Offer
The key to making the protocol work as we designed is to create a proper offer for the handshake. The offer must be deterministic and computable by both sides. Moreover, it should not be static: we want it to be changed from game to game, and also from round to round.
The main reason for that is to lower the probability that the opponent can learn our strategy, or that their strategy accidentally coincides with our protocol, giving them the win.
Additionally, the offer must be not to bad for us, so that we don’t give away free points. If the opponent accepts the offer while we are still trying to perform the handshake, we won’t lose too much.
Before we describe the algorithm for calculating the offer, let’s go back to the game rules:
- Both players know which items are on the table for bargaining
- Each player receives the round number and the opponents offer in each round
- All communication, like http calls or some IO, is not allowed.
- In every game there is a randomisation of the bargaining items
From the rules, we can see that the only common information between the two players are the group of bargaining items, the offer, and the round number. Moreover, the only information that passes between two players is the offer.
Thus, we built the protocol offer as follows:
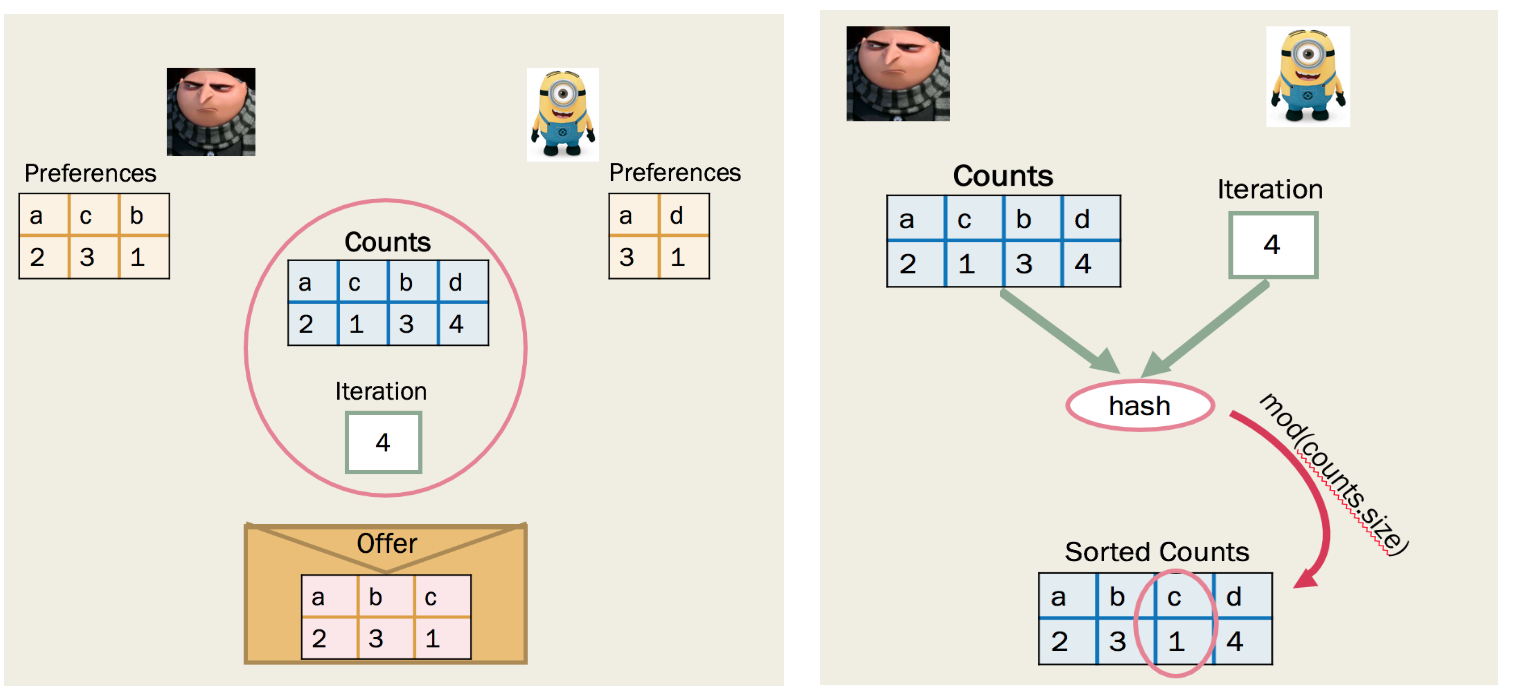
For each round we need to create an offer that will fulfil the requirements described above. In order to do so, we decided to create an offer by picking a single item in each round. We offer a single instance of this item to the competitor, keeping the rest of the items to ourselves.
This way we try to minimise the worth of the offer to the competitor, while also minimising our loss if they accept it.
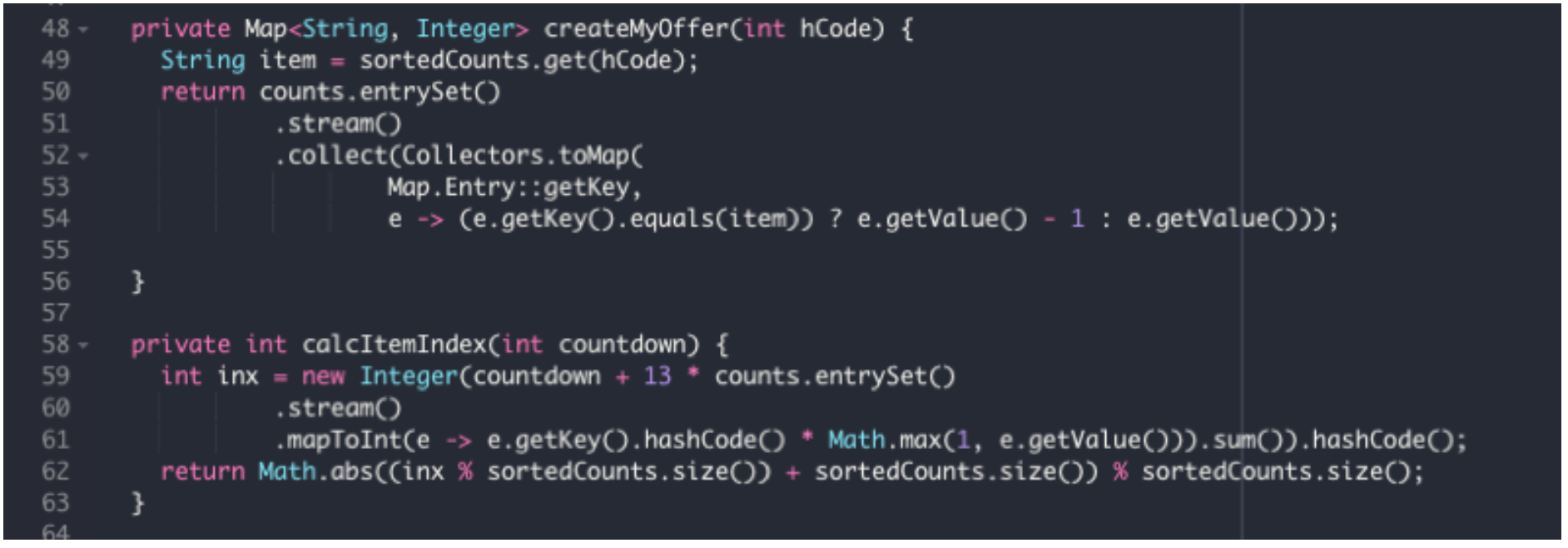
In order to choose the item to offer the opponent we hash the items and amounts in “Counts” along with current round number. We sort the items in “Counts” by their names and amounts, then use the hashed value we calculated modulo the size of “Counts” to choose the item to offer. “Counts” changes every game, and the round number every round, meaning that the hash value will be different in every round of every game.
This is a snippet of the offer code
Competitive Strategy
We started the game by developing a strategy for playing the game by the book – no Minions. We compared the results of several different kinds of strategies, from the simplest greedy algorithms to attempts to analyse the opponents’ preferences and build an offer accordingly. In the end, in order to emphasise the strength of the Overlord-Minion coalition we chose one of the simpler attempts. This was to show that even with a “bad” strategy the Minions could elevate the Overlord to the winning position.
We’ll describe the two basic directions we developed:
1. Greedy:
During the initialisation phase we built a static list of “best offers”. These were offers that ensured we got as many points as possible, sorted in descending order of value to us. We assumed that an offer which gave nothing to the opponent would not be accepted. Thus all the “best offers” included some items to be given to the opponent. The “best offer” options were hardcoded for each round. We tried several different configurations, sometimes allowing for more losses, sometimes for less. Finally, we compared the results of several such players and chose one for the basic master strategy.
2. Algorithmic:
The algorithmic strategy was to try to give the opponent the best deal we thought we could, while ensuring that our own gains would not fall below a certain threshold.
We kept a score for each item in counts, based on the number of times the opponent was willing to offer it to us. Our assumption was that the opponent was more likely to offer us items that were worth less to them. We sorted the items by their perceived importance to the opponent and built an offer containing items we thought were important to them, while not giving over items with the highest worth to us. This was an attempt to “sweeten the deal”. In this case we both win, but hopefully we win more. Here too we played with different configurations. This was done by changing amounts of attractive and unattractive items to the opponent, and playing with our threshold value. This strategy showed promising results, but was nowhere near those of the Overlord-Minion collaboration.
Results
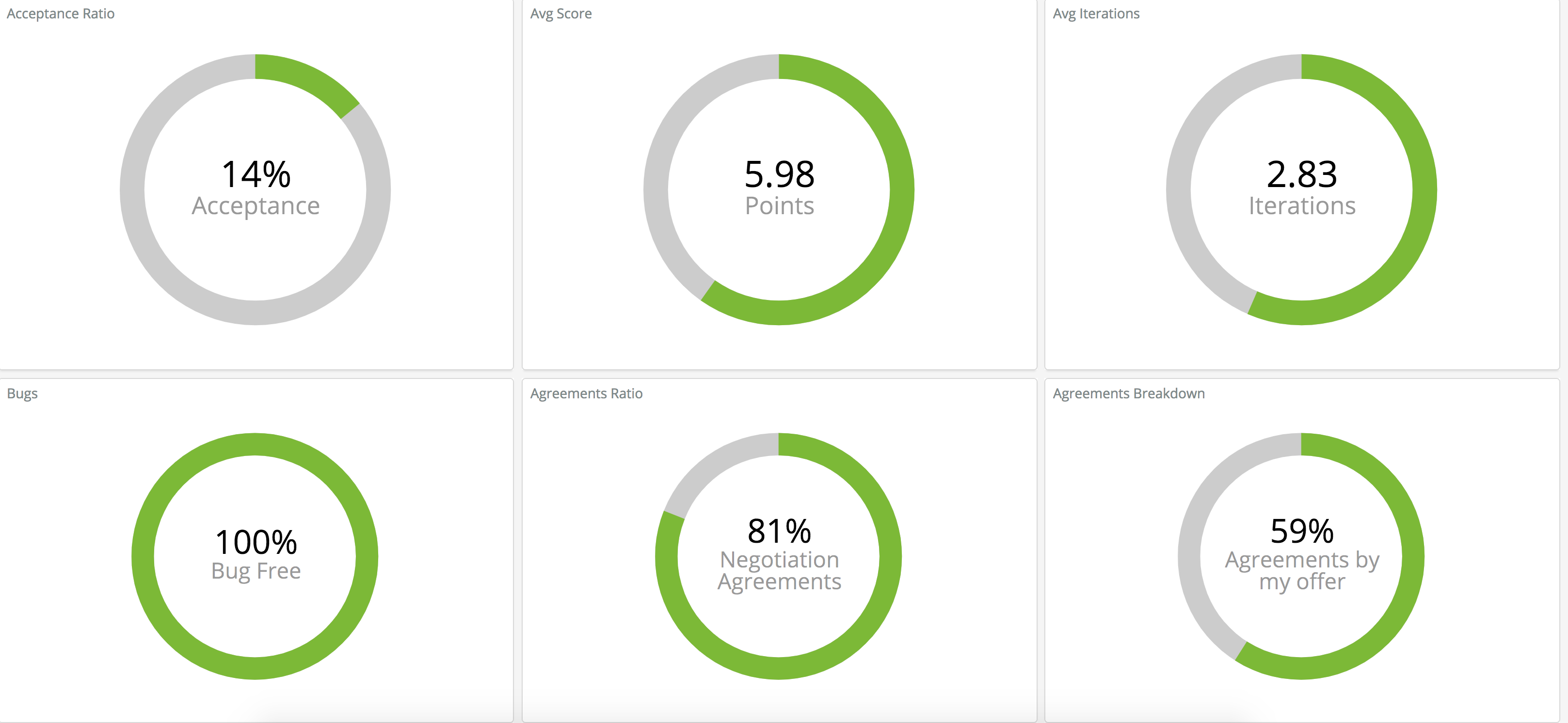
The final result of the game was the crushing defeat of all those who dared to oppose us.
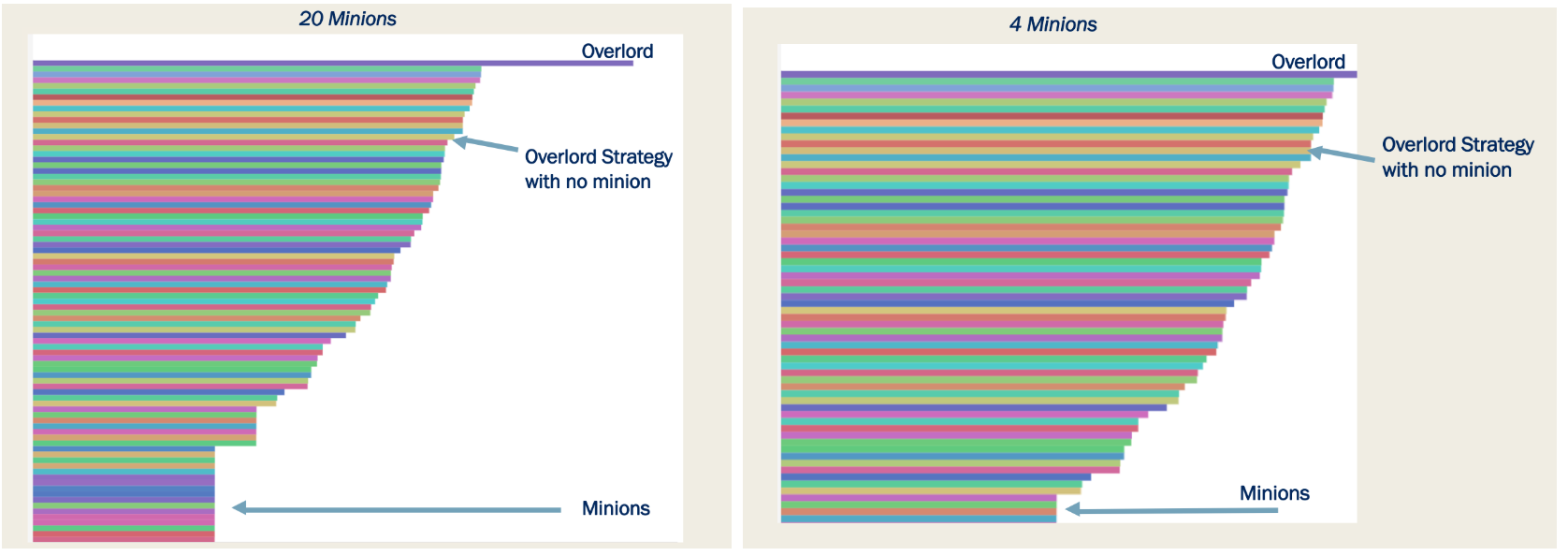
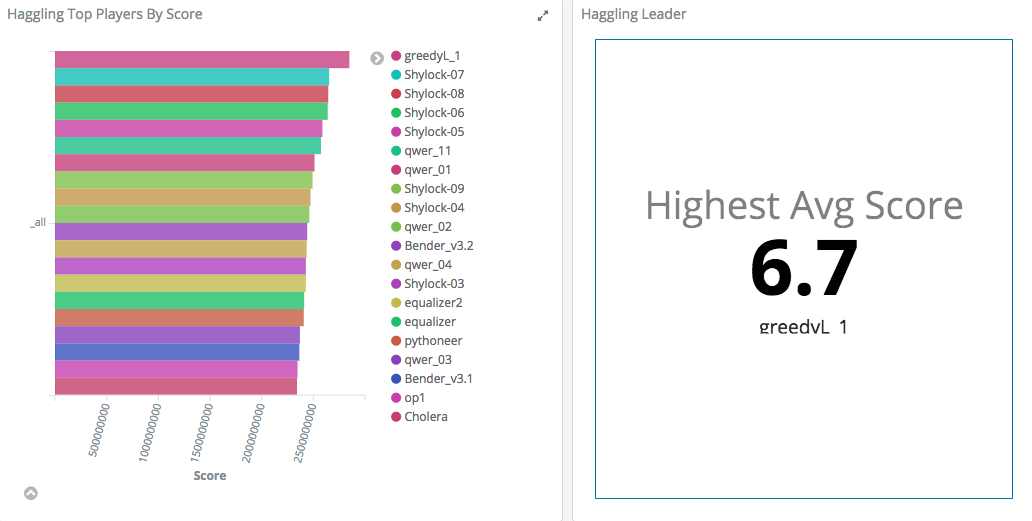
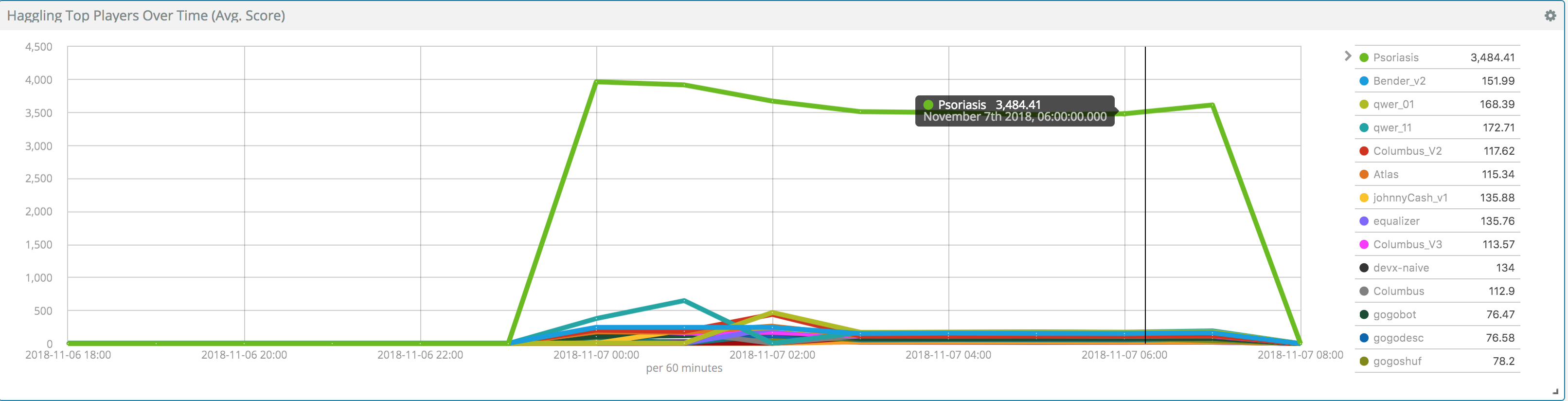
We can bask in our glory all day, but it is more interesting to describe the way we reached this victorious result. As we mentioned above, we felt that keeping a low profile was imperative to winning the game. The multiple hacking attempts and the general competitive atmosphere only served to strengthen this decision. Once we had finished working on the code we started to carefully test how much of a lift the Minions offered. The graph on the right is from a couple of days before the end of the competition. We enabled four minions, and saw that the Overlord immediately shot ahead of the competitors. We quickly disabled the minions, so as not to draw attention. In the final hour before the end of the game we enabled 20 minions, giving us the enormous lead seen in the graph on the left.
All hail the Overlord!
P.S.
Stay tuned to hear about how the game was hacked, and the different hacking strategies used by Roy Bass.