Overview
The role of a Data Scientist, or Machine Learning engineer, is becoming more and more valuable in the tech industry. It is the fast growing job in the U.S. according to a LinkedIn study, and was recently ranked as the best job in America by Glassdoor.
However, the life of a Data Scientist isn’t easy – the job requires good Math and Statistics knowledge, programming background and experience, and “hacking” skills, in order to get things done. This is especially true when handling huge amounts of data of different types.
We, at the personalization team at Outbrain, decided to try and take out the pain of data science, and make our life easier to allow us to perform effective research with immediate production effect.
In this post series I will describe an end-to-end machine learning framework we developed, over Apache Spark, in order to address the different challenges our Data Scientists and Algorithm Engineers face.
Outbrain’s recommendation system machine learning challenge:
Our goal is recommending stories the user is most likely to be interested in, given the user’s interests and the current context.
We need to rank the stories in our inventory by the probability that the user will click to read, and display the top stories to the user.
Our supervision is the past user actions – given a user and a document with a set of features, did the user click or not.
Our data and features:
Outbrain generates a lot of data.
We get over 550 million unique monthly users, generate over 275 billion recommendations monthly and have more than 35 million clicks a day.
The first part to computing quality recommendations, is representing well our key players: The users and the documents.
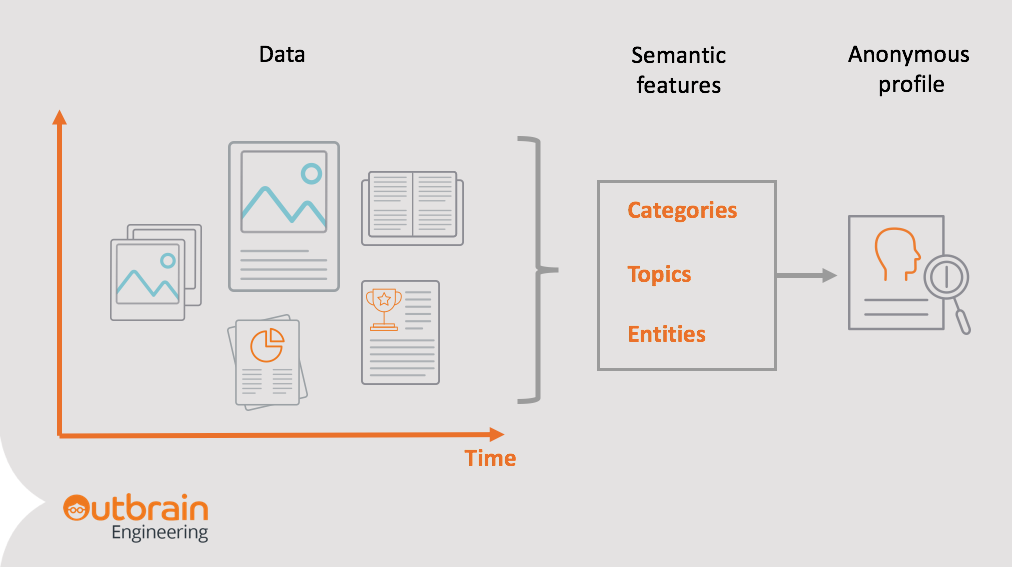
We extract semantic features from each document that has our widget installed, using an NLP engine. The engine extracts semantic features on some levels of granularity, from high level categories to very granular entities.
For example, on the ‘Westworld’ story below, we extract:
- High-level categories, such as entertainment.
- Lower level topics – such as TV or murder.
- Entities – persons, locations or companies, that the document discusses.

We represent our readers with similar semantic features.
We create an anonymous profile for each reader, based on content they were reading.
Each profile is an aggregation of the semantic features of each document the user read before.
Predictive models:
We use a variety of models, from three main types:
Content based models –
These models assume that there is a semantic connection between the documents the user likes to read.
The model uses the user profile, to find more documents that have similar semantic features to the ones we found out the user likes.
These could be stories within the same categories, from the same sites or covering a specific person or location.
Behavioural models –
Rather than assuming the user will want to keep reading documents on similar topics, it looks for connections between user interests, to other potential subjects that go well together.
For example, it may find that users that showed interest before on retirement investing, will be interested in the future on heart disease articles.
Collaborative models-
The third type, and potentially most powerful and interesting, are collaborative models.
These models use the wisdom of the crowd in order to recommend new content, potentially without the need to semantically understand it.
The basic idea is to find out readers with similar reading patterns; Find out what they like, in addition to the current user; and recommend these items.
Algorithms in this family use algebraic dimensionality reduction methods, such as Matrix Factorization or Factorization Machines, or finding a new, latent representation of the users and items using Deep Learning neural networks.
The process of data modeling consists of many common tasks.
To make this process efficient and enable agile research and productization, we have developed a general framework on top of Spark, containing 5 independent components.
Framework overview:
The system’s key components:
- Data collection
- Feature engineering
- Model training
- Offline evaluation and simulation
- Model deployment

The same system is used for both research and analysis of new algorithms, and also for running production models and updating them on a regular basis.
Next week, in part 2 of this blog post series, we will dive into the data collection flow which is a key ingredient to machine learning flows, and see how data is made more accessible using an automated Spark process.
Part 3 will cover our modeling framework, developed on top of Spark, that allows us to be highly agile with our research tasks, and dynamic as well as robust in pushing our models to production. Stay tuned!
Shaked is an Algorithm Engineer and Tech Lead at the Personalization team @ Outbrain's Recommendations group, developing large-scale machine learning algorithms for Outbrain's content recommendations platform, from data science to production.
1
Hi,
I miss the on-line model testing and model tuning component being displayed as well.
Stay tuned for part 3 of the post, will be discussed there!