
When we were considering migrating our data delivery pipeline from batches of hourly files into a real time streaming system, the reasons we had in mind were the obvious ones; to reduce the latency of our processing system and to make the data available in real time. But as soon as we started to work on it, we realized that there are quite a few additional good reasons to embark on this complex project.
Overview
Our data delivery pipeline is designed to deliver data from various services into our Hadoop ecosystem. There it is processed using Spark and Hive in order to produce aggregated data to be used by our algorithms and machine learning (ML) implementations, business reports, debugging, and other analysis. We call each type of this data a “datum”. We have more than 60 datums, each representing a different type of data, for example: request, click, listings, etc.
Outbrain is the world’s leading content discovery platform. We serve over 400 billion content recommendations every month, to over 1 billion users across the world. In order to support such a large scale, we have a backend system building from thousands of micro services running inside Kubernetes containers on top of an infrastructure that is spread over more than 7000 physical machines spread between 3 data centers and in public clouds (GCP & AWS).
As you can imagine, our services produce lots of data that is passed through our data delivery pipeline. On an average day, more than 40TB is moving from through it, and on peak days it can pass the 50TB.
And yes, in order to support this scale, the delivery pipeline needs to be scalable, reliable and lots of other words that end with “able”.
Pipeline Architecture
As I wrote above, we have multiple data centers (DCs), but in order to simplify the diagram and explanation, I will use only 2 DCs to present our pipeline architecture. As we go through the two architectures (legacy hourly and current RT), you will notice that the only components which remain the same are the edges. The services that produce the data, and the Hadoop where the data ends up.
Another thing worth mentioning is that in order to have full disaster recovery (DR), we have 2 independent Hadoop clusters in separated locations, each one of them gets all the data and processes the same jobs independently, in case one of them goes down, the other continues to work normally.
Hourly Files Pipeline – legacy
The data is collected by the services, and saved to files on the local file system of each service. From there, another process copies those files to our Data Processing System (DPS), which is an in house solution that collects all the data and copies it into the Hadoop. As you can see, it is a very simple architecture without a lot of components, and is quite reliable and robust since the data is saved in files which can be easily recovered in case of any malfunction.
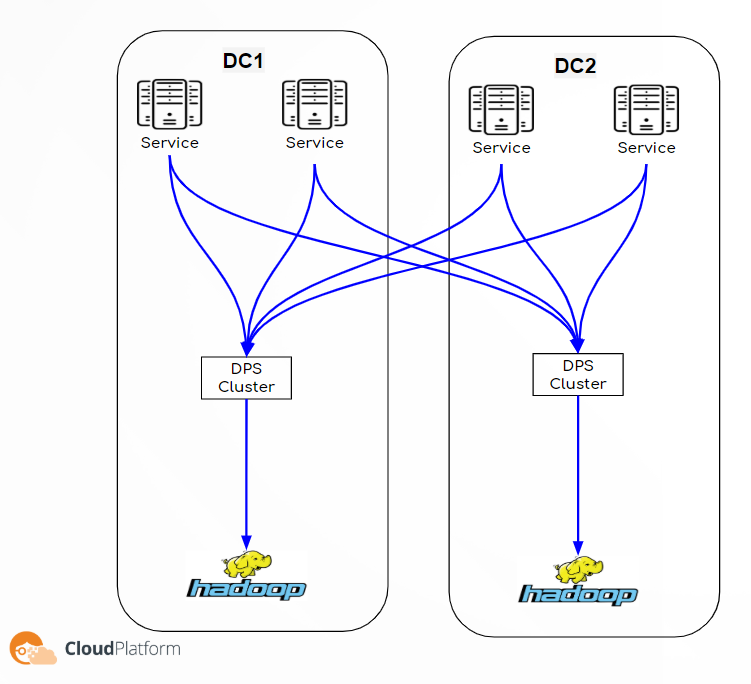
The drawbacks of this pipeline is that the data is moved in chunks of hours and it is not accessible during the duration of the delivery time. It is only available for processing after each hour is completed, and all the data is in the Hadoop. And it also places a heavy burden on the network because the data is transferred in spikes.
Real Time Streaming Pipeline
Replacing the local file system storage, we have a Kafka cluster. And, instead of our in house DPS system we have a MirrorMaker, an aggregated Kafka cluster and a SparkStreaming cluster.
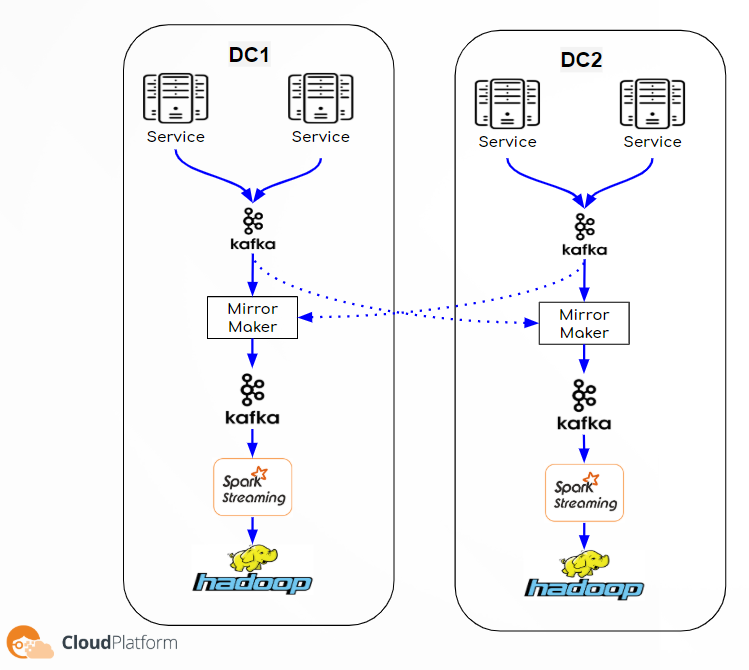
In this pipeline, the data is written directly from the service to the Kafka cluster. From this point all the data is accessible to anyone that wants to use it. Analysts, algo developers, or any other service that can find it useful. Of course it is also available to the MirrorMaker, as part of the pipeline.
The MirrorMaker job is to sync data between Kafka clusters, and in our case, to make sure that each aggregated Kafka cluster will have the entire data from all DCs.
Like before, the data in the aggregated cluster is available to all, especially to our SparkStreaming cluster which runs various jobs that consume the data and writes to the Hadoop.
So it’s clear that by implementing this pipeline, the data is available to all, and it reaches the Hadoop faster.
Obvious Benefits
Now lets go over the obvious benefits of the real time pipeline:
- Data availability – since the data is passed through Kafka clusters, it is available to all implementations that need real time data. Here are 2 good examples:
- Recommendation engines can now calculate its algo models with fresher data. This led to a lift of more than 16% in our Revenue Per Mille (RPM).
- We added real time customer facing dashboards which enable them to take required actions faster according to fresh data.
- Reduced the latency of the processing system – since the data reach the Hadoop faster, the hourly jobs that wait for the hourly data can start work sooner and to complete their work much closer to the end of the hour. This reduced the overall latency of the processing system and now the business reports for example, are available in a shorter time.
Additional Benefits
And those are the unexpected benefits that we gain from the real time pipeline:
- Network capacity – In the hourly files pipeline, the data is moved in hourly batches and at the end of each hour. This means that the network capacity needs to support movement of all data at once. This requirement forces us to allocate the required bandwidth while it is used only for a short time during each hour, wasting expensive resources. The real time pipeline moves the same amount of data incrementally over the course of the hour.
The graphs below demonstrate the bandwidth savings that we made once we moved to the real time pipeline. For example, in the RX graph, you can see that we moved from peaks of 17 GBPs to have flat bandwidth of 7 GBPs, saving 10 GBPs.

Total RX traffic

Total TX traffic
- Disaster recovery – the fact that in the hourly based pipeline the data is saved in files on the local file system of the machines that run the services have some limitations.
- Data loss – as we all know, machines have 100% chance of failing at some point. And when you have thousands of machines, the odds are against us. Each time a machine goes down, you have the risk of data loss since all the hourly files may not have been copied into the pipeline yet. In the real time pipeline, the data is written immediately to the Kafka cluster which is more resilient and the risk of the data loss is reduced.
- Late processing – if a machine has recovered from a failure, and you were lucky enough to avoid data loss, the recovered data needs to be processed and in most cases it won’t be done within the time period that the data is related to. This means that this time period will be processed again which adds extra load on the Hadoop and may result in data delays, since the Hadoop needs to process multiple time periods at the same time. Like before, the benefit of the real time pipeline in that aspect is that the data reaches the Hadoop without any delays so there is no reprocessing of any time period.
Conclusions
Having the real time pipeline, our life became much simpler. Beside the planned goals (data availability and reducing the latency), the extra goodies that we got from this change made us less sensitive to any network glitch or hardware malfunction. In the past, each one of those issues forced us to handle data delays and have the risk of data loss, and now the real time pipeline by its nature, solved all of them.
Yes, there are more components that we need to maintain and monitor, but this cost is justified if you compare it to the great results we achieved by implementing this real time system for our data delivery pipeline.
Director of Data Engineering @ Outbrain's Platform Group, developing large-scale data systems for Outbrain's content recommendations platform.