One of the main responsibilities of the DataInfra team at Outbrain, which I am a member of, is to build a data delivery pipeline, our pipeline is built on top of Kafka and Spark Streaming frameworks. We process up to 2 million requests per second through dozens of streaming jobs.
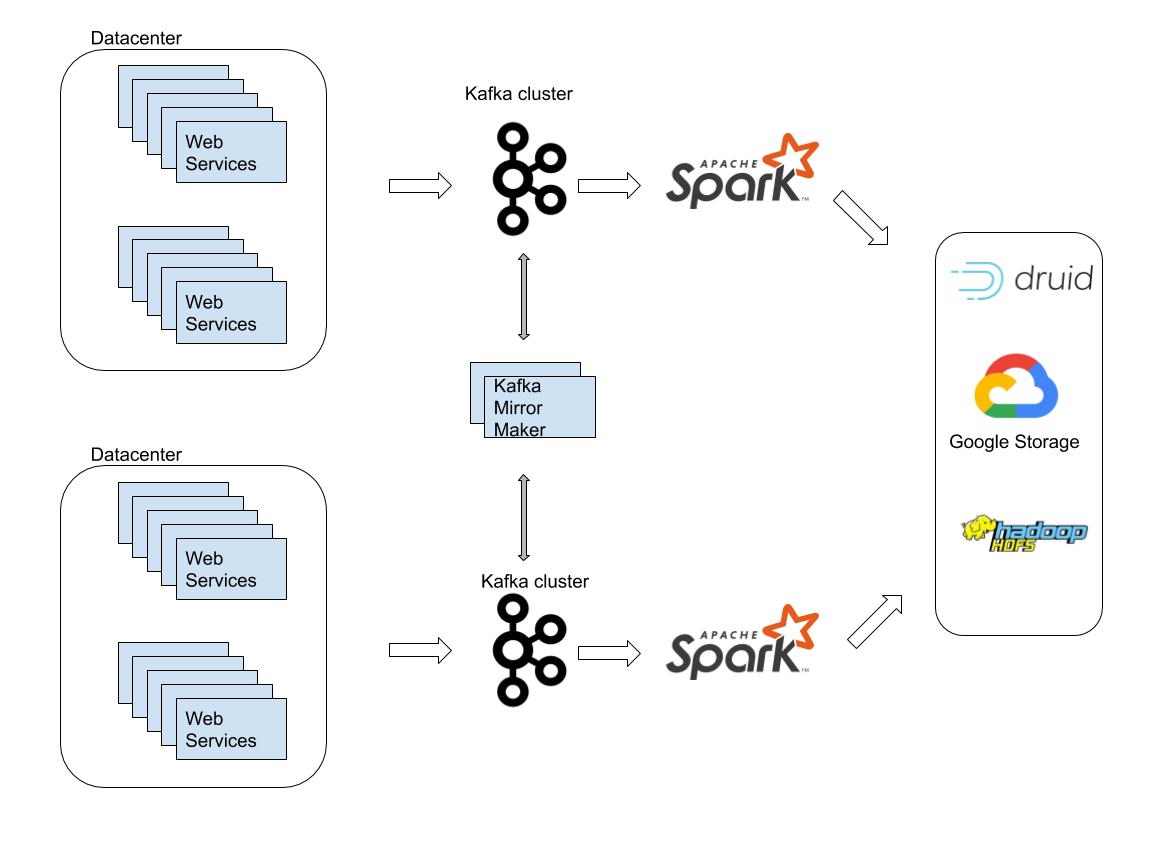
fig 1: Simplified data flow architecture
Problem Description
One of our requirements was to read data from different Kafka clusters and stream the data to the same path in the HDFS. This doesn’t sound complicated, several identical jobs, each provided with the Kafka address as a parameter. In practice, two concurrent jobs may delete each other files, here is how:
When we call saveAsHadoopFile() action in the spark program
https://gist.github.com/poluektik/7b15007bd94183deb0a8ea6acb71c684#file-hadoop-blog-post-gist-a
https://gist.github.com/poluektik/7b15007bd94183deb0a8ea6acb71c684
The save action will be performed by SparkHadoopWriter, a helper that writes the data and in the end issues a commit for the entire job.
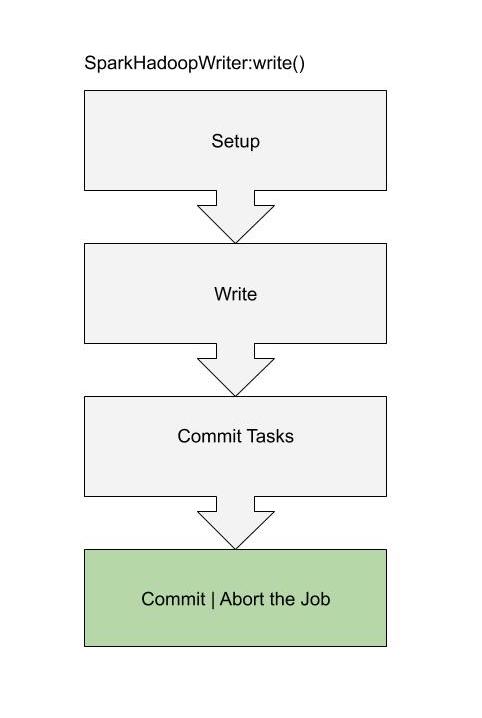
See relevant documentation for SparkHadoopWriter:
https://gist.github.com/poluektik/5e54c2117f5db692c02c6472a5866d46
The commit is the part that is most relevant to our problem. The class that by default does the commit is FileOutputCommitter which, among other things, creates ${mapred.output.dir}/_temporary subdirectory where the files are written and later on, after being committed, moved to ${mapred.output.dir}.
In the end, the entire temporary folder is deleted. When two or more Spark jobs have the same output directory, mutual deletion of files will be inevitable.
(OutputCommitter Documentation)
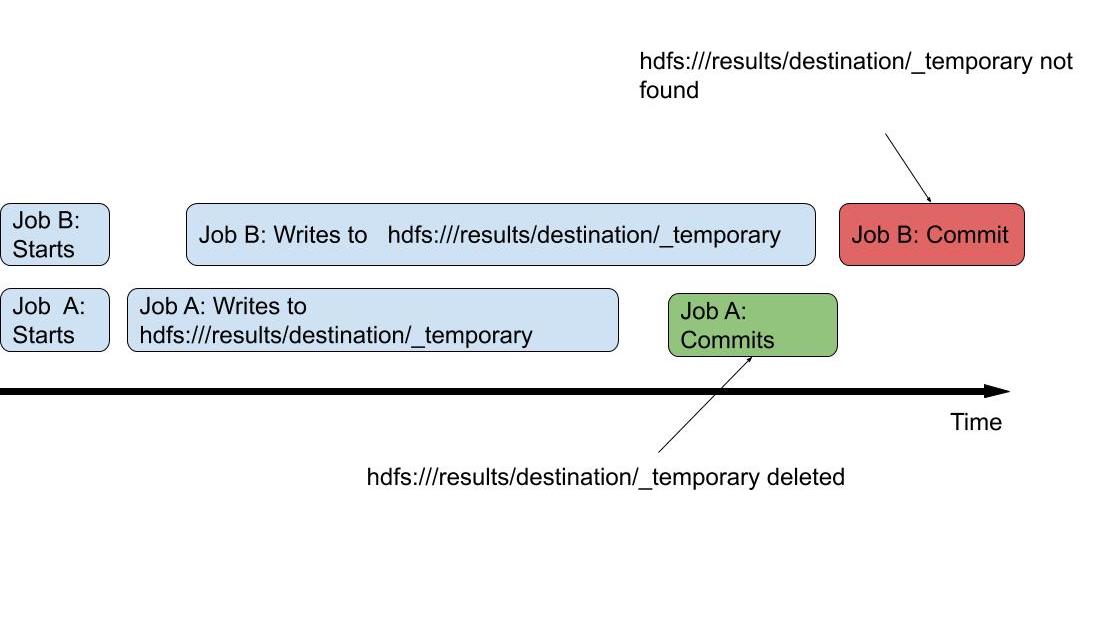
I’ve tried to find an easy solution in the Stack Overflow and Spark community but couldn’t find anything, except for suggestions to write to different locations and use Distcp later on, which would require additional compute resources which I’d like to spare.
The solution:
We’ve created our own OBFileOutputCommitter which is almost identical to the default FileOutputCommiter, but it supports the change of the temporary configuration, fortunately, we can add our own committer through Spark configuration. This way each job will have its own temporary folder, so the cleanup won’t delete data of other jobs.
There is a catch, of course – You’ll have to use MultipleTextOutputFormat to make sure that the files have unique names. If you won’t, two jobs will have the same default names which will collide.
Here is the link to the custom committer code. Add it to your project and follow the example below.
https://gist.github.com/poluektik/d0481bbc93a8ffaf8f527516e200f9dc
Conclusion
The Hadoop framework is flexible enough to amend and customize output committers. With proper documentation,
it could have been easier, but that shouldn’t stop you from trying to alter the framework to suit your needs.
References
https://github.com/apache/spark/pull/21286
https://issues.apache.org/jira/browse/MAPREDUCE-1471?jql=text%20~%20%22FileOutputCommitter%22
https://issues.apache.org/jira/browse/MAPREDUCE-7029