
Working in an infrastructure team is different from working in a development team. The team develops tools that are used by developers’ teams inside Outbrain. It is very important to provide a convenient way for working with new technologies. Having a Spark cluster enables running distributed data processing in scale. Until now developers worked with Spark writing ad-hoc crontab jobs in production. It created a messy and unstable environment and required manual maintenance in case of failure. For that reason, our team wanted to give an infrastructural way for working with Spark.
In this blog post, I explain how we built the solution implementing Spark to be a native tool in our WorkflowEngine.
Meet WorkflowEngine
The Outbrain Data Infrastructure team enables running hundreds of ETL jobs every hour. These jobs are orchestrated by WorkflowEngine – an internal tool, which is developed by the team.
The WorkflowEngine (WFE) enables running various types of transformations from many kinds of data sources: MySQL, Cassandra, Hive, Vertica, Hadoop etc., located in two data centers and the cloud. Every transformation, or flow, implements some business logic. A flow may contain several tasks, which are executed one after another.
Flows are developed and owned by researchers, data scientists and developers in other groups at Outbrain, such as Algorithm research groups, BI and Data Science.

Defining flows in WFE gives users a lot of benefits. It enables users to autonomously specify dependencies between flows, so when one flow ends, another is triggered. In addition, users can define a number of retries for their flows, so if a flow fails for some reason, WFE reruns it. If all retries fail, WFE sends an email or alert about the flow failures. Logs for each running flow are shown in a convenient form in WFE UI. Furthermore, WFE collects metrics for all flows, which enables us to track the health of the system.
From the operational perspective, several instances of WFE are deployed on machines which are owned by the infrastructure team, users just define ETL flows in a separate repository.
Diving Into the Solution
In order to respond to requirements for running data analytics on Spark, our team had to allow an infrastructural way for running Spark jobs orchestrated by WFE. To achieve this, we’ve developed a new kind of WorkflowEngine task called SparkStep.
When approaching the design for SparkStep, we had several principals in mind:
- Avoid producing additional load on WFE machines
- Create an isolated environment for every Spark job
- Allow users to specify and at the same time allow the system to limit the number of YARN resources allocated for every SPARK job
- Enable using multiple Spark clusters with different versions
Taking all this into consideration, we came up with the following architecture:
Keeping the control while having fun
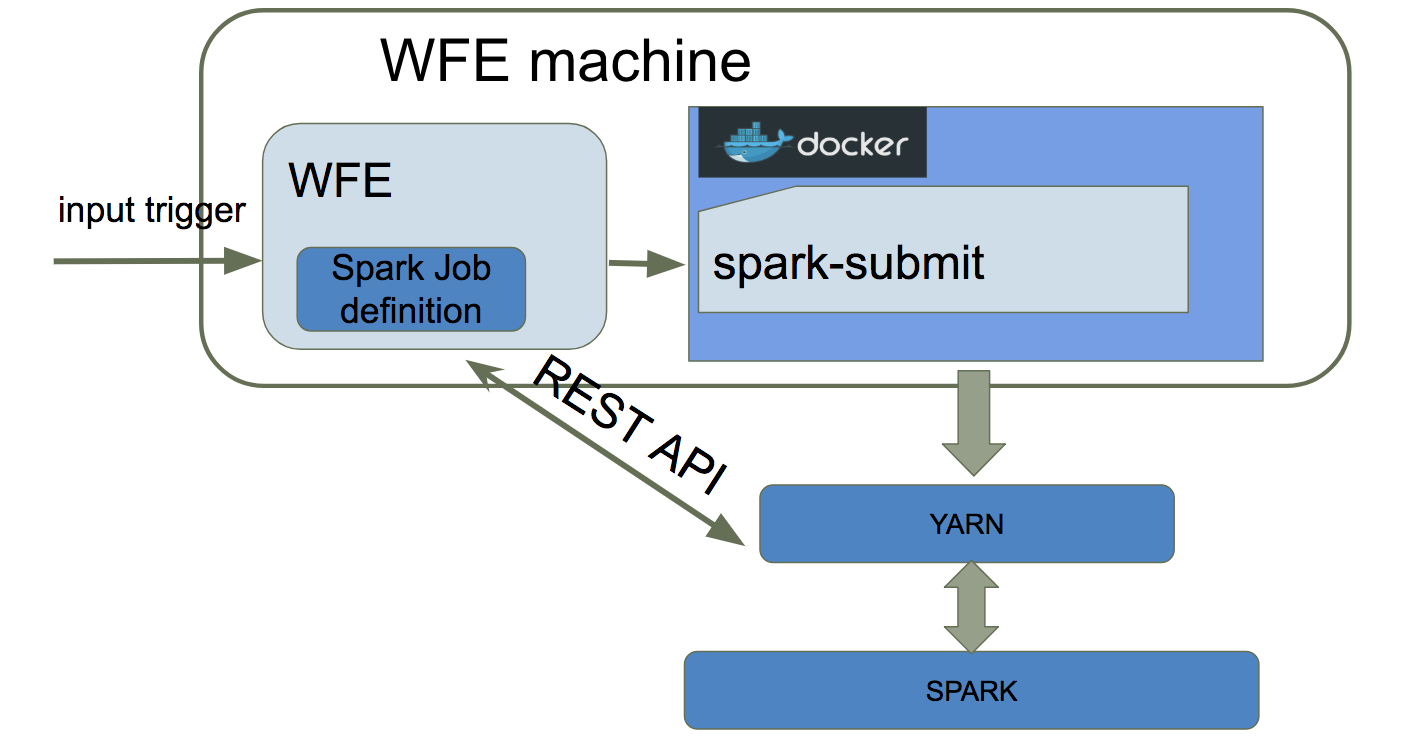
The Spark job definition specifies how a job will run on the Spark cluster (e.g. jarURL, className, configuration parameters). In addition, there are properties that are set internally by WFE. When WFE starts executing a SPARK job, it builds a spark-submit command using all these properties.
The spark-submit command submits the Spark job to YARN, which allocates needed resources and launches the application. After submitting the job, WFE constantly checks its status using YARN REST API. When the job is completed in YARN, WFE reports a COMPLETED status for the WFE Spark task and continues running the next task. However, if the Spark job fails in YARN, WFE reports a FAILED status for the WFE job. In this case, WFE can rerun the job, according to the defined number of retries. If the job runs in YARN for too long, and its running time exceeds the defined maximum, WFE stops the job using the YARN REST API. In this case, the job is marked as FAILED in WFE. This functionality ensures both that we have a cap on the amount of resources each flow can use and that resources are saved when a job is canceled for any reason.
The spark-submit command runs in a Docker container. The Docker exits once the job is submitted to the cluster. It enables us to create an isolated environment for every Spark job executed by WFE. In addition, using Docker container, we can easily use different Spark versions simultaneously, by creating different Docker images.
By using this architecture we achieve all our goals. Spark jobs are submitted to YARN in a “cluster” mode, so they do not create a load on WFE machines. YARN handles all resources for each job. Every Spark job runs in an isolated environment owing to the Docker container.
I am a Data Infrastructure Engineer in Outbrain's platform group, developing solutions for large-scale data delivery and data processing systems.