The Cloud is an Illusion
Cloud service providers have enabled innovations in many areas of our society from the way we watch movies to the way we share media with our family and friends. Companies can focus on amazing products without having to worry about managing data centers, servers, networking equipment, and all of the complexities therein.

But the cloud is an illusion, just an abstraction. Behind every cloud are data centers full of countless racks of servers, routers, firewalls, and engineers who design, deploy, and manage them. There is physical infrastructure that powers the technology we enjoy everyday and, at Outbrain, we run the majority of our workloads on bare metal infrastructure. We are, for that matter, our own cloud provider. This post is a peak behind the curtain of how we do this, at scale.
It was a sunny day in California…
In the summer of 2017, our new West Coast data center went live, along with our first fully automated 10G network deployment. It was a great success, which is why we wanted to also roll it out in our other data centers. The new mission was to migrate every server from our legacy 1G network to our shiny new 10G network. Essentially, this meant installing 10G network cards and running new twinax cabling to a good number of thousands of servers. No biggie… except:
- The vast majority of those servers run production workloads
- Many of them run stateful applications such as data stores (mysql, elasticsearch, etc.)
- Many of these stateful applications can only tolerate a limited amount of downtime before they start shuffling (a lot of) data around
- Servers need to be migrated around the clock, with no downtime to any cluster
- The application and networking engineers are in Israel
- The physical server engineers are in NYC
- There is a 7 hour time difference between NYC and Israel (the workweek also only overlaps for 4 days of the week)
- The on-site technicians who work on our servers cannot log into them for reboots, health checks, etc.
How many Engineers does it take to…?
Let’s take a look at everything that goes into a manual migration of one server, so we can better understand the task at hand. We will narrow the focus to one specific case: migrating a mysql node to the new network.
The people involved:
- Gerry – Data Center Server Engineer (NYC)
- Yuval – Data Storage Engineer (Israel)
- Adi – Networking Engineer (Israel)
- Mike – On-site Remote Hands technician (non Outbrain employee)
The process:
- Yuval removes the mysql server from the cluster and makes sure that the cluster is still healthy.
- Gerry properly powers down the server, and sends the location details to the remote hands team. Based on the location of the server within the rack, he also lets them know which switch ports to use.
- Mike opens up the server, installs the 10G network card, and runs redundant twinax cabling to the 10G switches. He powers it back up, connected to both the legacy and the 10G networks.
- Adi prepares the server to join the 10G network and reboots it for the final changes to take effect. After the reboot, he checks that the server is indeed part of the new network and that both twinax connections are up and stable.
- Yuval adds the server back to the mysql cluster and makes sure everything looks healthy.
- Mike removes the old RJ-45 cables and waits for Yuval and Gerry to prepare and shut down the next server (to avoid multi-node shutdown in the same cluster).
* This is a simplified explanation of the process, and assumes everything goes as smooth as possible. It involves 3 Outbrain engineers to be available across a major time zone difference + on-site remote hands. That’s 4 engineers to migrate a single node.

And now that we’re done, there’s only… a few thousand servers left to migrate…running on various types of hardware, with different versions of Linux, different applications and operating under different availability restrictions.
Which begs the question – Will it Scale?
Putting Remote Hands in the Driver Seat
After a few iterations, this is what the process looks like from Outbrain’s perspective:
- Gerry executes a Rundeck job with one mouse click, and then emails Mike a list of server locations.
- Gerry goes to sleep.
This is the process from the perspective of a remote hands technician at the data center:
- Mike receives a list of server locations, and plugs an iPad into the first server on the list.
- The iPad is running Slack and the chat room starts displaying new messages. It lets Mike know that the server is attempting to safely stop mysql and power itself down.
- The server shuts itself down, but right before it goes down, it sends a message to the Slack channel explaining all the next steps, including which switch ports to connect to server to.
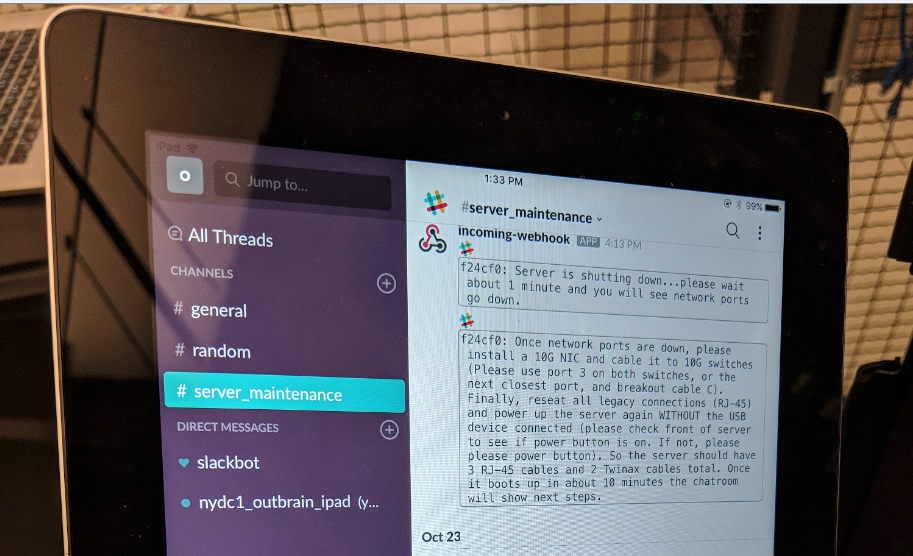
- Mike installs the 10G network card, finishes up the cabling, and powers the server back up.
- The server runs the network preparation scripts, reboots itself, checks the network status, starts up mysql, runs health checks, and lets Mike know that it’s time to remove the old cabling and move on to the next server.
Meanwhile, Gerry and Yuval’s teams are getting updates via email every time a server begins and succeeds the migration process. They can monitor the Slack channel during the process, or even look back at all of the migrations in a Kibana dashboard. If anything ever goes wrong, the iPad communicates that Mike should stop and contact Outbrain. The iPad won’t take any wrong actions if it is plugged into the wrong server or reseated at any point.
How We Built It
When the iPad is plugged into the server, it is recognized by a udev rule. This triggers a wrapper script that contains all of the migration logic. Here’s a deeper look at the individual steps and components:

Rundeck is used to put the desired servers into maintenance mode. It does this by touching empty files onto the servers that indicate that they are in maintenance mode, and they are in the first stage of the network migration process.
Chef contains all of the necessary scripts to run the migration. This includes the udev rules and the wrapper, networking, and application specific scripts. The Chef recipe chooses the proper pre and post migration scripts based on the role of the server.
UDEV Rules are very powerful, and we use them define what happens when the iPad is plugged into a server:
SUBSYSTEM=="usb",
ACTION=="add",
ENV{ID_SERIAL}=="Apple_Inc._iPad_averylonguniqueserialnumber",
RUN+="/path/to/wrapper_script.sh"
This rule roughly translates to: “When a usb device with this serial number in plugged into the server, run the following wrapper script”
A custom startup script is what triggers the wrapper script when the server boots back up after a shutdown or reboot to perform the next migration step.
The wrapper script holds all of the logic and functionality of the process.
- It only runs if a maintenance file exists on this server.
- It checks for a state file, and depending on what it finds, understands which part of the migration process to run next.
- It sends the event logs (for the Kibana dashboard), emails (to the proper teams who manage this server), and Slack messages (via webhooks).
- It handles the reboots and shutdowns.
- When it runs an application specific pre/post migration script, it’s expecting to get an exit status of 0 (or else it will let everyone involved know that something went wrong).
- When it runs the network preparation script (which is worthy of its own blog post), it can make a few decisions based on the exit status. It can rings the alarms, move on to the next step, or even let the remote hands technician know that one of the twinax cables seems loose and should be fully seated.
- It cleans up by removing all migration related files, including itself.
More time to build more automation =]
Now we can set a bunch of servers to maintenance mode, hand off the list of server locations to remote hands, and continue our daily work while they are migrated.
And since this works so well using the current approach, work is underway to generalise the concept and make it available to many other types of physical maintenance.
So that our cloud can continue to build itself… while we sleep.