Outbrain Challenges the Research Community with Massive Data Set



Outbrain is responsible for content recommendations you see on thousands of online publishers, including CNN, Fox News, ESPN, and the Washington Post. These recommendations must satisfy a large variety of user interests, which ultimately require a lot of data and advanced algorithms.
Introducing the Outbrain Challenge
Today, we are excited to announce the release of our anonymized dataset that discloses the browsing behavior of hundreds of millions of users who engage with our content recommendations. This data, which was released on the Kaggle platform, includes two billion page views across 560 sites, document metadata (such as content categories and topics), served recommendations, and clicks.
Our “Outbrain Challenge” is a call out to the research community to analyze our data and model user reading patterns, in order to predict individuals’ future content choices. We will reward the three best models with cash prizes totaling $25,000 (see full contest details below).
The sheer size of the data we’ve released is unprecedented on Kaggle, the competition’s platform, and is considered extraordinary for such competitions in general. Crunching all of the data may be challenging to some participants—though Outbrain does it on a daily basis.
Sample Test Case: Predicting What Content Recommendation a User Will Click On
On the left: content recommendations presented to the user. On the right: the user’s reading history
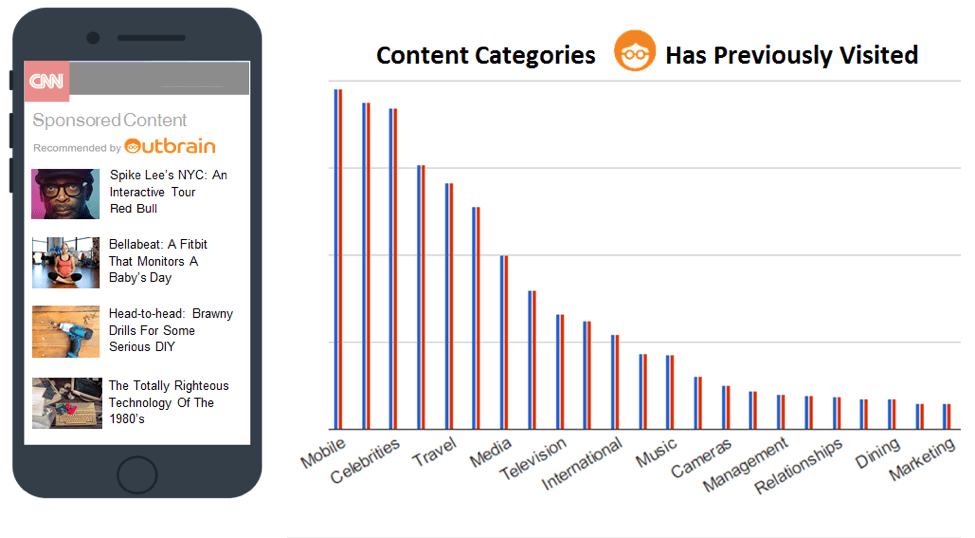
Here are some key questions researchers will need to consider, based on this test case.
1. User interest matters, but how and to what extent?
Consider your own content consumption tastes and choices. If you tend to read content about sports and technology, and you specifically read more about Usain Bolt and Elon Musk, would you be more inclined to click on a story about the latest Kim Kardashian scandal or a story about SpaceX? And what if the choice was between a Red Bull video about extreme sports and the SpaceX story? What is ultimately the best formula for mixing the interests of one user with the wisdom you gain from a larger pool of users?
2. Context matters, but how and to what extent?
If you are reading an article about a new restaurant, would you prefer to read next about another restaurant? Or would you rather read about cooking? Or perhaps you would be interested in a completely different topic. Outbrain currently captures context from many different variables. For example, the device of the user, the time of day, her current location, the current content she is reading, whether she came from another section on the publisher, or from Facebook.
3. Breaking news matters, but how long before a story is no longer interesting?
Some content is evergreen. Other news grows stale almost immediately. How can you determine when interest in a story diminishes?
Official Contest Details
Analyze and Model Data: Win Cash Prizes and Glory
The Outbrain Challenge will be hosted on Kaggle, an online platform for predictive modelling competitions. Companies and organizations such as Facebook, AirBnb, Microsoft, Walmart, and even the European Organization for Nuclear Research upload data challenges on Kaggle. Data Scientists from all over the world experiment with different techniques and compete against each other to produce the best models, winning both prestige and monetary rewards.
The Outbrain Challenge will award the best three models with cash prizes: $12,000 for first place, $8,000 for second, and $5,000 for the third best model.
Data is Completely Anonymized:
Our data is anonymized across multiple fronts. First, user identifiers are opaque. Outbrain does not collect nor hold personally identifiable information (PII), and the user identifiers we are releasing here are further obscured. Second, to protect our publisher partners and advertisers, we are not releasing URLs of viewed or clicked stories, but rather opaque document and site identifiers. We are also not releasing the text of the stories, only some of their semantic attributes such as encoded categories and entities these stories pertain to.
Important dates:
The Outbrain Challenge will open on October 5, 2016, and close at 11:59PM UTC on January 18, 2017.
