Upgrading your datacenter network with the push of a button
Intro
In this blog post, I am going to share with you the story of how we automated switch upgrades, to perform them at scale. First, however, I recommend reading one of our previous blog posts, to get a better understanding of our network environment: Switches, Penguins and One Bad Cable
To upgrade?
It all started with a PagerDuty call – a failed switch in one of our datacenters. One support ticket later, and our vendor says it’s time for a firmware upgrade. On all of our switches. We flinched. We’ve done this many times before and somehow, there were always edge cases, weird states, and other loose ends. Upgrading a single switch? it was a hassle we were used to, which thankfully didn’t happen too often. Frankly, not a big deal. But upgrading a fleet of 200? uh…
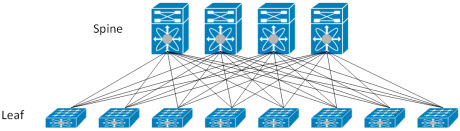
Just to get you up to speed, our network environment is based on Clos fabric, or more specifically, a leaf spine topology. BGP is the dynamic routing protocol that glues it all together.
We’re using Cumulus Linux as the operating system of our switches, Chef to manage their configuration and Jenkins to automate provisioning. In case you haven’t read the article in the intro and you’re wondering what I mean, here’s a link to it again.
So let’s jump straight to it. How do we upgrade switch firmwares at Outbrain? Simple. We don’t. We re-provision them instead. In case you’re not sure what I mean, I’ll clarify.
Switch Re-provisioning Process
Cumulus Linux is a Linux distribution designed for switches. As such, you can manage it using standard Linux tools, and you can also install it using standard Linux methodologies, such as using PXE boot. Except in the case of switches, PXE boot is replaced with the Open Network Install Environment (ONIE).
Once a switch is instructed to re-provision, on the next boot the following things will happen:
- The switch requests an IP address via DHCP
- The DHCP server acks and responds with DHCP option 114 for the location of the installation image
- The switch uses ONIE to download the Cumulus Linux disk image, installs, and reboots
- Success! You are now running Cumulus Linux
By the end of this process, we have an updated firmware (OS) version running on the switch without any special configuration. Just like a brand new switch.
“But what about the config?” you might ask. Excellent question! In a word, ZTP. In three words, “Zero Touch Provisioning”:
- The switch boots to a fresh Cumulus Linux version (see step 4 of ONIE above)
- The management interface (eth0) is configured by default for DHCP
- eth0 sends a DHCP request
- The DHCP server returns a URL for a ZTP script
- The ZTP script installs the Chef client, configs and runs it
- Chef-client runs our homemade run_list
Once the Chef client run completes successfully, the switch is fully configured with all the relevant configuration tailored for it. BGP sessions are established and the switch will be back in production.
Now that you have a grasp of the process, here’s what it actually takes to re-provision a switch:
- “onie-select” selects ONIE mode to use during the next boot
- “-i” means “Install Boot”: at the next reboot, load ONIE in ‘install’ mode. This installs a new operating system, overwriting the current one
- “-f” means “Force the operation”: assumes “yes” to any questions the script might ask
- “&& reboot” will reboot the switch only if the previous onie-select command succeeded
15 minutes later, and the switch is back in the game, running an updated firmware and its own tailored config. Pretty cool, right? Now we just have to do that to 74 switches, which is what we have in a datacenter.
15 minutes times 74 is…
… a lot. Especially if you add some validations pre and post “re-provisioning”, which bring you to 30 minutes per switch. Multiplied by 74? 2220 minutes, which is 37 hours. That’s a lot of time to be babysitting switches. Not to mention failures, edge cases, missing a switch or two…
And that’s just one datacenter. Multiplied by 3, that’s 6660 minutes, which is 111 hours. So if you spend 8 hours every day doing just this, one switch at a time, with nothing failing at all, it would take you about 2 weeks of repetitive work to do the full upgrade.
There must be a better way. A smarter way. A faster way. A way that is:
- Automated
- Robust
- Hands-free
- Auditable
A better way
3 days later and we have something to show for. Allow me to introduce you to our “Switch Upgrade Automation” process (notice that “has a catchy name” wasn’t part of the requirements).
The “switch upgrade automation” process is a Ruby-based program running inside a docker container. It is built as a Jenkins job which is executed periodically. The program covers all the necessary validations to pick a valid candidate switch, re-provision it and make sure the switch is ready to be put back into production.
Diving into the process, each Jenkins build will spawn a docker container, getting the following arguments (there’s actually more, but we’ve chosen the main ones):
- Datacenter name
- Switch type: leaf or spine
- Switch OS version to upgrade from
- The 1st or 2nd switch in the rack
Automated and Robust
We first check if there is already a running build, as we don’t want two switches re-provisioning at the same time. We took the conservative approach and decided to run the process serially. Also, we don’t want to move on to the next switch if the previous one failed, as there may be a problem with the process, environment or switch itself.
Next, we build a dynamic Prometheus query that returns a list of all switches running the OS version we’re upgrading from. Using this list we choose a random switch and trigger yet another Prometheus query. The additional query allows us to retrieve the following information about the candidate switch:
- Global health status – a metric built out of many local tests running on the switch, including hardware sensors, ztp_exit_status, services status, and PTM
- BGP peer status – number of established BGP peers
- Number of Active links
Using these values we can then build a data structure containing the switch name, the metric values, and the validation phase: the pre-upgrade status. Remember this structure, we’ll come back to it later.
switch_list.each do |switch|
puts "Candidate switch for upgrade: #{switch}"
switch_data_structure = {
switch => {
'pre' => {},
'post' => {}
}
}
switch_data = fetch_switch_data(switch_data_structure, switch, switch_type, 'pre')
...
We now have the pre-upgrade status of the candidate switch however, this is not enough. We also need to validate the functionality of the candidate’s sibling switch (the other switch in the rack) before taking any action. We run the same Prometheus query again to retrieve the metrics we’d mentioned above, but this time for the sibling switch. The name of the sibling switch and its metric values are inserted into the pre-upgrade status.
sibling_switches = get_sibling_switches(switch, switch_type, switch_list)
sibling_switches.each do |sibling|
sibling_data_structure = {
sibling => {
'pre' => {},
'post' => {}
}
}
sibling_data = fetch_switch_data(sibling_data_structure, sibling, switch_type, 'pre')
switch_data.merge!(sibling_data)
end
...
Compare the candidate switch with its sibling: if they match, or the upgrade candidate has fewer active links / BGP neighbors than its sibling (amongst other metrics), we’re good to go – we know we won’t lose connectivity to any of the machines in the rack. This gives us the confidence to run the re-provisioning process while there are active workloads in the rack.
Cross-checking switch metrics with sibling switch: leaf-r32-p1-pod1 <> leaf-r32-p2-pod1
leaf-r32-p1-pod1: ----> {"bgp_peer_status"=>"32","interface_link_status"=>"37","health_global_status"=>"0"}
leaf-r32-p2-pod1: ----> {"bgp_peer_status"=>"32","interface_link_status"=>"37","health_global_status"=>"0"}
Status: Pre upgrade validation passed!
Sending changelog for switch leaf-r32-p1-pod1
Sending leaf-r32-p1-pod1 to Re-provisioning, command is '/root/run_switch_provision.sh -F'And if validation fails? the process would skip this candidate switch and elect a new candidate instead.
Hands-free and auditable
Just before rebooting our candidate switch, we silence alerts, so as to not disrupt our on-call while the process runs in the background. Also, to make sure we know “what happened, when and why”, we use our in-house changelog mechanism to fire a “machinelog” event for future auditing. What are these changelog and machinelog things? They’re another blog post waiting to be written.
With all pre-provisioning validations, alert masking and audit events out of the way, it’s showtime! We trigger the Switch Re-provisioning Process for our elected candidate switch and send it for a reboot.
Once rebooted, we monitor whether the switch accepts connections on TCP port 9100, which is the Prometheus node exporter port. Why? Because we’re using Chef to install the Prometheus node exporter, which gives us a good indication that Chef (which is the final provisioning step) completed successfully. In addition, node exporter is in charge of exposing switch metrics, on which we rely for post-provisioning validation. Once we manage to establish a connection, we know the switch is up again, running the new OS.
Last but not least, we need to validate that our switch is in the same state as it was prior to re-provisioning. We want to make sure we haven’t lost any links, peers, etc. How do we do that?
Remember the pre-upgrade status we saved when we started the validation process? It’s time to get the post-upgrade status and compare the two. Basically, it means running the same query as before, building the data structure and running a diff. If all is well, the process completed successfully and we can move on to the next candidate. If not, we abort and notify a team member that something went wrong.
Retrieving switch metrics: leaf-r32-p1-pod1 Upgrade_phase: post
Prometheus query: count(fabric_switch_bgp_peer_status{instance=~"leaf-r32-p1-pod1"}==0) - Prometheus response: 2
Prometheus query: count(fabric_switch_bgp_peer_status{instance=~"leaf-r32-p2-pod1"}==0) - Prometheus response: 2
Prometheus query: count(fabric_switch_interface_link_status{instance=~"leaf-r32-p1-pod1"}==2) - Prometheus response: 7
Prometheus query: count(fabric_switch_interface_link_status{instance=~"leaf-r32-p2-pod1"}==2) - Prometheus response: 7
Prometheus query: fabric_switch_health_global_status{instance=~"leaf-r32-p1-pod1"}==0 - Prometheus response: 0
Prometheus query: fabric_switch_health_global_status{instance=~"leaf-r32-p2-pod1"}==0 - Prometheus response: 0
Data for switch: leaf-r32-p1-pod1.nydc1.outbrain.com was validated SUCCESSFULY after upgrade
So what just happened?
If you’ve read carefully so far, you might notice that we haven’t gone into time savings in this whole process. We chose not to parallelise re-provisioning at this time, to make sure our blast radius, in case of failure, is limited to a single rack. However, we removed the human factor from the process, which means it can run the full 2 weeks in the background and let us know when things are done (or not working as expected). This, in turn, frees us to deal with the more important aspects of running a production system at scale.