פוסט זה נכתב במקור כפוסט אורח בבלוג המצויין “Software Archiblog — בלוג ארכיטקטורת תוכנה” של ליאור בר-און.
לעבור לארכיטקטורת מיקרו-services, זה לא פשוט. צריך להשקיע הרבה: הרבה תכנון, הרבה מחשבה, ולא מעט זמן לביצוע העבודה. מה שבטוח שאם תחפשו בגוגל תוכלו למצוא אינסוף מדריכים, הוראות, הנחיות וסיפורי מורשת קרב איך לוקחים service בעל מבנה מונוליטי ומעבירים אותו לארכיטקטורת מיקרו services.
כולם ימכרו לכם שלארכיטקטורה הזו יש יתרונות כמו:
* בסיס קוד קטן, פשוט וקריא. כל service מבצע מספר קטן של משימות, ויש לו אחריות מאוד מוגדרת.
* ממשק וגבולות ברורים לכל service, ולכן יש גם בעלות ברורה שעוזרת לשיפור האיכות.
* כל service נכתב בטכנולוגיה שמתאימה לו ולצוות שאחראי עליו.
* ה service עולה יורד באופן מהיר יותר, ולכן מתאים מאוד לפריסה מתמשכת (Continuous Deployment).
* משפר את יציבות מערכת – אם service אחד נפל, service-ים אחרים ממשיכים לתפקד. אם service אחד עמוס אפשר בקלות להתקין שרתים נוספים שיריצו את אותו השירות.
ה tutorials שתמצאו, כנראה ידברו על שירותי רשת (web services) – ללא UI ובעיקר ללא ניהול session. אבל מה עם אפליקציות רשת (web applications), שם ה UI, וניהול ה session של המשתמש הם החלקים המרכזים ? האם גם אותם ניתן לפצל ל ״מיקרו-אפליקציות״ ? נניח שלקחת אפליקציה אחת ובדרך קסם פיצלת אותה לשניים, איך תתמודד עם:
* שמירה על חווית כניסה (login) אחת?
* מעבר חלק, ושיתוף session בין האפליקציות?
* מניעת שכפול קוד ?
בוא ניקח לדוגמה אפליקציית רשת נפוצה: אתר של חברת סטארטאפ.
כמו שכל בית צריך מרפסת, כל סטארטאפ צריך אתר. מה יש באתר? ובכן, זה לא רק אתר שיווקי. זהי אפליקציית רשת שמאפשרת ללקוחות להשתמש במוצר ולתפעל אותו בשירות עצמי. למשל: המשתמשים יכולים לקבוע פרמטרים, לשנות הגדרות, להוריד דוחות וגרפים. יש גם כמובן מנגנוני רישום והתחברות, הגדרת פרופיל משתמש, שחזור והחלפת ססמה, CAPTCHA, וכו’.
האתר לרוב יהיה מהמערכות הוותיקות בחברה – ולכן גם עם חוב טכנולוגי גבוה / Technology Stack ישן.
לכאורה מועמד מצוין לשדרוג ולמעבר לארכיטקטורת מיקרו services, אבל אליה וקוץ בה: דווקא אפליקציית רשת קשה מאוד לפצל ויש מעט מאוד מידע ברשת כיצד לעשות זאת.
פוסט זה יתאר ארכיטקטורת מיקרו-אפליקציות (Micro-Apps Architecture) שמטרתה (בדומה ל Micro-Services Architecture) לסייע בפיצול אפליקציית רשת למיקרו אפליקציות ובכך ליהנות מהיתרונות המדוברים.
אז איך עושים את זה ?
בשלב הראשון ננתח את המבנה הלוגי של האפליקציה. סביר להניח שאפליקציה שמשרתת כמה וכמה תרחישים, תורכב מכמה אזורים עיקריים.
כל אזור (אדום, צהוב או כתום) הוא מועמד להיות מיקרו אפליקציה עצמאית.
בשלב השני נוציא כל אזור מתוך האפליקציה ונהפוך אותו למיקרו אפליקציה. מהי מיקרו אפליקציה? מיקרו אפליקציה היא אפליקציה שאחראית על פונקציונליות ברורה מוגדרת ומצומצמת. לדוגמה משרתת סוג לקוחות מסוים, או חושפת יכולות של מוצר מסוים משלל המוצרים של החברה.
כשבאים לקבוע את הגבולות בין האפליקציות ניתן להשתמש באותם שיקולים בהם משתמשים בחלוקת service , למיקרו .services.
המיקרו אפליקציה בנויה מטכנולוגיה המתאימה לה ולצוות שלה ומותקנת על שרת ייעודי. האפליקציה יכולה להגיש גם את צד הלקוח (client side) וגם את צד השרת (server side). האפליקציה מותקנת בתוך ה firewall ולא מקבלת תעבורת רשת באופן ישיר.
נייצר service מארח (hosting service) דרכו עוברת כל התעבורה למיקרו אפליקציות. ברוב המקרים ניתן להשתמש באפליקציה המקורית (המונוליטית) כ service מארח, כיון שאחרי שהוצאנו מתוכה את רוב הפונקציונליות כנראה שנותר שם רק התשתית של ניהול הsession, אימות המשתמש, אבטחה וכו’.
ה service המארח משמש כמעין נתב. ״נתב על סטרואידים״, אם תרצו.
למה נתב? כי ה service המארח רק מקבל את הבקשה דרך התשתיות הבסיסיות ומשמש כצינור בכדי להעביר את הבקשה למיקרו אפליקציה הרלוונטית.
למה סטרואידים? כי עדיין יש שם נקודת החלטה ולוגיקה המותאמת למוצר שלכם. לדוגמה: איך לבצע אימות פרטי המשתמש, מהיא המיקרו אפליקציה ברירת המחדל אליה יועבר המשתמש לאחר הכניסה, ניהול cookies, טעינת פרטי המשתמש לזיכרון-המטמון אחרי login, מימוש של הפרוקסיים, וכו.
מה עושה הפרוקסי?
* הפרוקסי הוא יחידה לוגית בתוך ה service המארח. תפקידו להוות צינור ולהעביר בקשות מהלקוח למיקרו אפליקציה עליה הוא אחראי. התקשורת בין הפרוקסי למיקרו אפליקציה באמצעות פרוטוקול HTTP. לכל מיקרו אפליקציה קיים פרוקסי משרת אותה.
* כל פרוקסי נרשם על מסלול אחר של ה URL. לדוגמה כל בקשה למשאב תחת הכתובת www.yoursite.com/app1 תופנה לפרוקסי האדום.
* כשהבקשה מגיעה לפרוקסי כבר ידוע מיהו המשתמש, ולכן הוא יכול להעביר את שם המשתמש (או כל מידע אחר עליו) למיקרו אפליקציה באמצעות HTTP Header.
* הפרוקסי מנהל את כמות החיבורים הפתוחים לאפליקציה שלו, ומדווח על כמות החיבורים הפתוחים למערכת הניטור.
* הפרוקסי מקבל בחזרה את התשובה מהמיקרו אפליקציה ומעביר אותה חזרה למשתמש.
יתרונות – או מה יצא לנו מכל זה?
* הפרדה ברורה בין אפליקציות: זליגת זכרון במיקרו אפליקציה אחת לא תביא לנפילה של מיקרו אפליקציה אחרת.
* ה service המארח הופך מהר מאוד לתשתית שבה אין הרבה פיצ’רים חדשים. הוא הופך לפשוט וקל יותר לתחזוקה.
* כל מיקרו service נכתב בטכנולוגיה שמתאימה לדרישותיו ולצוות שמפתח אותו.
* ניתן לעשות את המעבר מאפליקציית רשת מונוליטית למיקרו אפליקציות בשלבי, ובכך להקטין את הסיכון. לדוגמה:
* לייצר מיקרו אפליקציה שתגיש רק את קוד הלקוח שנכתב בטכנולוגיה חדשה, נניח ב AngualrJS, ולהשאיר את קוד השרת ב service המארח.
* לייצר מיקרו אפליקציה חדש שיגיש קוד שרת בלבד. ניתן להחליט שלא מעבירים קוד ישן אלא רק קוד חדש של פיצ’רים חדשים. וכך לבצע החלפה אטית אך שיטתית ומדורגת מתשתית שרת ישנה לתשתית שרת מודרנית יותר.
* ניטור — כל פרוקסי מדווח על כמות הכישלונות, הצלחות, מספר החיבורים התפוסים וכו’.
* רישום בקבצים – ה service המארח אחראי על כתיבת קבצי הגישה access log עבור כל המיקרו אפליקציות.
* אבטחה — ה service המארח מבצע את כל מנגנוני האימות של כניסת משתמשים ו CAPTCHA.
* אפליקציות חדשות — נניח שאתה רוצה לפתח אפליקציית-רשת חדשה. תוכל לממש אותה כמיקרו אפליקציה בתוך ה service המארח. כך תחסוך בפיתוח מנגנוני אבטחה, רישום וכניסה, כתיבת קבצי גישה וכו’, כל מה שתדרש זה להוסיף עוד חוק ניתוב service המארח. בנוסף לא תצטרך את עזרת אנשי ה OPS. גישה זו היא מיושרת עם רעיון ה DEVOPS.
כמובן שאין ארוחות חינם. אז מה אנחנו מפסידים?
* עוד תחנה במסלול — טיפול בבקשה של משתמש לוקחת זמן ארוך יותר.
* שיתוף קוד לקוח — כבר לא תוכל לשנות בקלות את ה JS/CSS שמשותפים עבור כל המיקרו אפליקציות. בכדי לשתף קוד לקוח (למשל ניווט בתוך האפליקציה), תצטרך להתייחס אל הקוד כאל ספרית צד שלישי. תוכל להשתמש ב bower בכדי לנהל את הגרסאות ולהעלות את הקוד ל repository. דרך נוספת תהיה להעלות קבצים משותפים ל CDN.
* הגדל הקושי בתחזוקה ובמציאת תקלות – כל תוספת של חלק נע במערכת מקשה על מציאת באגים. עוד קבצי לוג שצריך לבדוק כמשנסים לאתר תקלה. נניח שמשתמש מנסה לגשת למיקרו אפליקציה ומקבל HTTP CODE 403. יהיה עליכם לבדוק האם ה service המארח חסם את הגישה, או אולי האבטחה של המיקרו אפליקציה חסמה את הבקשה.
* הפרוקסים הם פשוטים ולא משוכללים כמו HAProxy.
הניסיון שלנו באאוטברין:
* פתחנו את הארכיטקטורה הזו בתחילת 2015, כאשר הבנו שאנחנו הולכים לחשוף הרבה יכולות של המוצר שלנו למשתמשי הקצה באמצעות שירות עצמי דרך אפליקציית רשת. אפליקציית הרשת שלנו הייתה מבוססת על תשתיות ישנות והבנו שמבחינה טכנולוגית אנחנו צריכים לבצע שדרג משמעותי.
* המטרה הייתה לפתח יישומים חדשים בטכנולוגיות מודרניות באופן בלתי תלוי ע”י צוותים שונים עם סט בדיקות שונה תוך כדי שיתוף session בין האפליקציות, כל זאת בלי לכתוב מחדש את כל התשתית של אפליקציית הרשת הקיימת.
* התחלנו עם מיקרו אפליקציה אחת, ועכשיו יש לנו 4 מיקרו אפליקציות שמגישות גם צד שרת וגם צד לקוח. הנה דוגמה ל Stack הטכנולוגי של 3 מארבעת מיקרו אפליקציות בתשתית של אאוטברין:
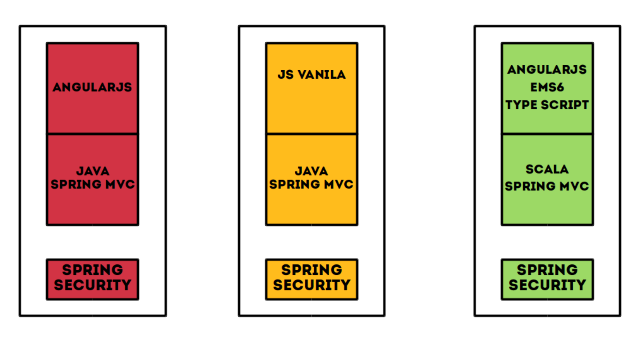
* לכל מיקרו אפליקציה יש מערכת בדיקות עצמאית וההחלטה האם אפשר לעשות Deploy ל production נמצאת בידי הצוות שמפתח את האפליקציה.
* לכל מיקרו אפליקציה יש ניטור משלה וההתראות מגיעות לצוות הרלוונטי.
* הוספנו ניטור ל service המארח בכדי לוודא שכמות החיבורים לכל מיקרו אפליקציה לא עוברת ערך מקסימלי וכמות השגיאות וההצלחות.
* קובץ הגישה ב service המארח חושף את כל הפעילות של המשתמש בכל המיקרו אפליקציות השונות ונותן מבט אחד על פעולות המשתמש.
* הוספת מיקרו אפליקציה נוספת היא מאמץ קטן של מספר שעות פיתוח.



