
Upgrade Railway Tracks Under a Moving Train
Outbrain has quite some relations with Cassandra. We have around 30 production clusters of
different sizes, ranging from small ones to cluster with 100 nodes across 3 datacenters.
Background
Cassandra has proven to be a very reliable choice as a datastore which employs an eventual consistency model. We used the Datastax Enterprise 4.8.9 distribution (which is equivalent to Cassandra 2.1) and as Cassandra 3 evolved clearly at some point we had to plan out an upgrade. We ended up with two options, either upgrade the commercial distribution version provided by Datastax or migrate to the Apache Cassandra distribution. Since Outbrain uses Cassandra extensively it was an important decision to make.
At first, we identified that we do not use any of the Datastax enterprise features and we were quite happy with the basics that are still offered by Apache Cassandra. So, at this point, we decided to give Apache Cassandra 3.1.11 a try.
But when planning an upgrade aside from the necessity to stay on the supported version there are always some goals, like leveraging a new feature and seeking for performance improvement. Our main goal was to get more from the hardware that we have and potentially reduce the number of nodes per cluster.
In addition, we wanted to have in-place upgrade which means that instead of building new clusters we could perform the migration in the production clusters themselves while they are still running, it is like upgrading the railway tracks under a moving train and we are talking about the very big train moving in high speed.
The POC
But before defining the in-place upgrade we needed to validate that the Apache Cassandra distribution fit to our use cases, and for that, we performed a POC. After selecting one of our clusters that will be used as a POC we build a new Apache Cassandra 3.1.11 cluster, following the new storage format and hence read path optimisations in Cassandra 3 we started with a small cluster of 3 nodes in order to see if we can benefit from this feature for reducing the cluster size – that is if we could achieve acceptable read and write latencies with fewer nodes.
The plan was to copy data from the old cluster using sstableloader – while the application would employ dual writes approach before we start the copying. This way we would have two clusters in sync, and we could direct our application to do some/all reads from the new cluster.
And then the problems started… at first it became clear that with our multiple datacenter’s configurations we do not want sstableloader to stream data to foreign data centers, we wanted to be able to control the target datacenter for the stream processing, we reported a bug and instead of waiting for a new release of Apache Cassandra we build our own custom build.
After passing this barrier we reached another one that was related to LeveledCompactionStrategy (LCS) and how Cassandra performs compactions. With a cluster of 3 nodes and 600GB of data in a table with LCS it took few weeks to put data into the right levels. Even with 6 nodes it took days to complete compactions following sstablesloader data load. That was a real pity, because read and write latencies were quite good even with a fewer number of nodes. Luckily Cassandra has a feature called multiple data directories. At first it does look like something to do with allowing more data but this feature actually helps enormously with LCS. So once we tried it and played with an actual number of data directories we identified that we can compact 600GB of data on L0 in less than a day with three data directories.
Encouraged with these findings we conducted various tests on our Cassandra 3.1 cluster and realised that not only we can benefit from storage space savings and faster read path – but also potentially put more data per node for clusters where we use LCS.

Storage before and after the migration
The plan
The conclusions were very good and indicated that we are ok with Apache Cassandra distribution and we can start preparing our migration plan using in-place upgrades. At the high level the
migration steps should be:
- Upgrade to the latest DSE 4.x version (4.8.14)
- Upgrade to DSE 5.0.14 (Cassandra 3)
- Upgrade sstables
- Upgrade to DSE 5.1.4 (Cassandra 3.11)
- Replace DSE with Apache Cassandra 3.11.1
After defining the plan, we were ready to start migrating our clusters. We mapped our clusters and categorised them according to if they are used for online serving activities or for offline activities.
Then we were good to go and started to perform the upgrade cluster by cluster.
Upgrade to the latest DSE 4.x version (4.8.14)
The first upgrade to DSE 4.8.14 (we had 4.8.9) is a minor upgrade. The reason this step is needed at all because DSE 4.8.14 includes all the important fixes to co-exist with Cassandra 3.0 during upgrade and our upgrade experience tells that indeed DSE 4.8.14 and DSE 5.0.10 (Cassandra 3.0.14) co-existed very well. The way it should be done is to upgrade nodes in a rolling fashion upgrading one node at a time. One node at a time applies to a datacenter only, datacenters could be processed in parallel (which is what we actually did).
Upgrade to DSE 5.0.14 (Cassandra 3)
Even if you aim to use DSE 5.1 you cannot really jump to it from 4.x, so 4.x – 5.0.x – 5.1.x chain is mandatory. The steps and pre-requisites on upgrade to DSE 5.0 are documented quite well by Datastax . What is probably not documented that well is which driver version to use and how to configure it so that application smoothly works both with DSE 4.x and DSE 5.x nodes during upgrade. What we did is that we instructed our developers to use cassandra-driver-core version 3.3.0 and enforce the protocol version 3 to be used so that the driver can successfully talk to both DSE 4.x and DSE 5.x nodes. Another thing to make sure is that before starting the upgrade you should ensure that all your nodes are healthy. Why? Because one of the most important limitations about clusters running both DSE 4.x and 5.x is the fact that you cannot stream data, which means that bootstrapping a node during node replacement is simply not possible. However, for clusters where we had SLAs on latencies we wanted more confidence and for those clusters what we did was that in one datacenter we upgraded a single node to DSE 5.0.x. This is 100% safe operation, since it’s the first node with DSE 5.0.x it can be replaced using the regular node replacement procedure with DSE 4.x. One very important point here is that DSE 5.0 does not really force any schema migration till all nodes in the cluster are running DSE 5.0.x. What this means is that system keyspaces remain untouched and this is what guarantees that DSE 5.0.x node can be replaced with DSE 4.x. Since we have 2 kinds of clusters (serving and offline) with different SLA we took 2 different approaches, for the serving clusters we upgraded the datacenters sequentially leaving some datacenter running DSE 4.x, we did it because if something goes really wrong, we still would have a healthy datacenter with DSE 4.x running. And for the offline clusters we upgraded all the datacenters in parallel, both approaches worked quite well.
Upgrade sstables
Whether clusters were upgraded in parallel or sequentially we always wanted to start sstablesupgrade as quick as possible after DSE 5.0 was installed. Sstables upgrade is the most important phase of upgrade because it’s most time consuming. There are not so many knobs to tune:
- control number of compaction threads with -j option for the nodetool upgradesstables command.
- control the compaction throughput with nodetool setcompactionthroguhput.
Whether -j would allow to speed up sstables upgrade depends a lot on how many column families you have, how big they are and what kind of compaction strategy is configured. As for the compaction throughput we determined that for our storage system it was ok to set it to 200 MB/sec to allow regular read/write operation to be carried out at reasonable higher percentile latencies, but for sure this has to be identified for each storage system individually.
Upgrade to DSE 5.1.4 (Cassandra 3.11)
In theory, upgrade from DSE 5.0.x to DSE 5.1.x is a minor one, just need to upgrade the nodes in a rolling fashion exactly the same way as minor upgrades were done within DSE 4.x, storage format stays the same and no sstablesupgrade is required. But when upgrading our first reasonably large cluster (in terms of number of nodes) we noticed something really bad, nodes running DSE 5.1.x suffered from never-ending compactions in the system keyspace which killed their performance while DSE 5.0.x were running well. For us, it was a tough moment because that was the serving cluster with SLAs and we did not notice anything like that on our previous clusters upgrades! We suspected that something is potentially wrong with schema migrations mechanism and the command nodetool describecluster confirmed that there are two different schema versions, one from 5.0.x nodes and one from 5.1.x nodes. So, we decided to speed up DSE 5.1.x upgrade under assumption that once all nodes are 5.1.x there would no issues with different schema versions and cluster would settle. This indeed happened.
Replace DSE with Apache Cassandra 3.11.1
So how was the final migration step of replacement of DSE 5.1.4 with Apache Cassandra? In the end it worked well across all our clusters. Basically, DSE packages have to be uninstalled, Apache Cassandra has to be installed and pointed to existing data and commit_log directories.
However, two extra steps were required:
- DSE creates dse-specific keyspaces (e.g. dse_system). This keyspace is created with EverywhereStrategy which is not supported by the Apache Cassandra. So before replacing DSE with Apache Cassandra on a given node the keyspace replication strategy has to be changed.
- There are few system column families that receive extra columns in DSE deployments (system_peers and system_local). So, if you attempt to start Apache Cassandra after DSE is removed – it will fail on schema check against these column families. There are two ways this could be worked around – the first option is to delete all system keyspaces, set auto_bootstrap to false and also set the allow_unsafe_join JVM option to true – assuming the node’s ip address stays the same Cassandra will re-create system keyspaces and jump into the ring. However we used alternative approach – we had a bunch of scripts which first exported these tables with extra columns to json – and then we imported them on a helper cluster which had the same schema as system tables do in Apache Cassandra. Then we imported data from json files and copied the resultant sstables to the node being upgraded
Minor version, big impact
So Cassandra 3.11 clearly has vast improvements in terms of storage format efficiency and better read latency. However even within a certain Cassandra major version a minor version can introduce a bug which would heavily affect performance. So the latency improvements were achieved on Cassandra 3.11.1. But this very specific version introduced an unpleasant bug (CASSANDRA-14010, fix sstable ordering by max timestamp in singlePartitionReadCommand)
This bug was introduced during refactoring – and led to that for tables with STCS almost all sstables were queried for every read. Typically Cassandra sorts sstables by a timestamp in a descending order – and it starts answering a query by looking at the most recent sstables until it’s able to fulfil a query (with some restrictions, like for counters or unfrozen collections). The bug however made sstables to be sorted in the ascending order. It was fixed in 3.11.2 – and here is the impact – number of sstables per read for 99th percentile has dropped after the upgrade. Reading less sstables for sure leads to lower local read latencies.

Drop in sstables per read
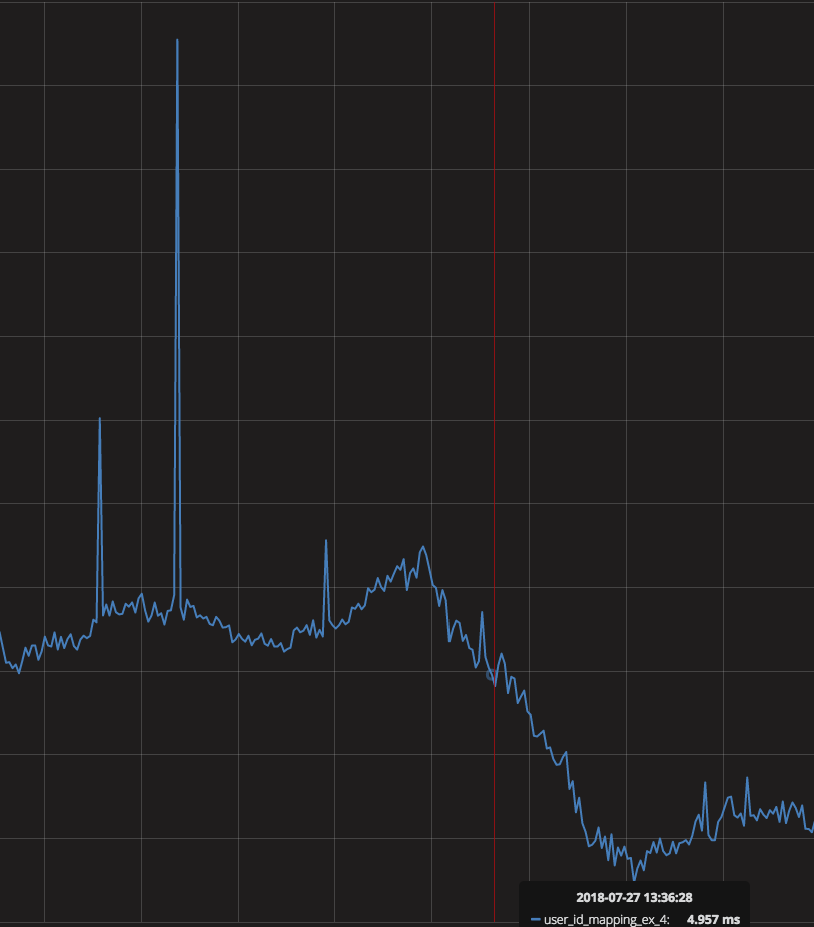
Local read latency drop on Cassandra 3.11.2
Always mind page cache
On one of our newly built Cassandra 3.11.2 clusters we noticed unexpectedly high local read latencies. This came as a surprise because this cluster was specifically dedicated to a table with LCS. We spent quite some time in blktrace/blkparse/btt to confirm that our storage by itself is performing well. However we identified later that high latency is only subject for 99th and 98th percentiles – while from btt output it became clear that there write IO bursts which result in a very large blocks thanks to a scheduler merge policy. Next step was to exclude compactions – so even with compactions disabled we still had these write bursts. Looking further it became evident that page cache defaults were different from what we typically had – and the culprit is vm.dirty_ratio which was set to 20%. With 256GB of RAM flushing 20% of it certainly would result in IO burst which would affect reads. So after tuning page cache (we opted for vm.dirty_bytes and vm.dirty_background_bytes instead of vm.dirty_ratio).
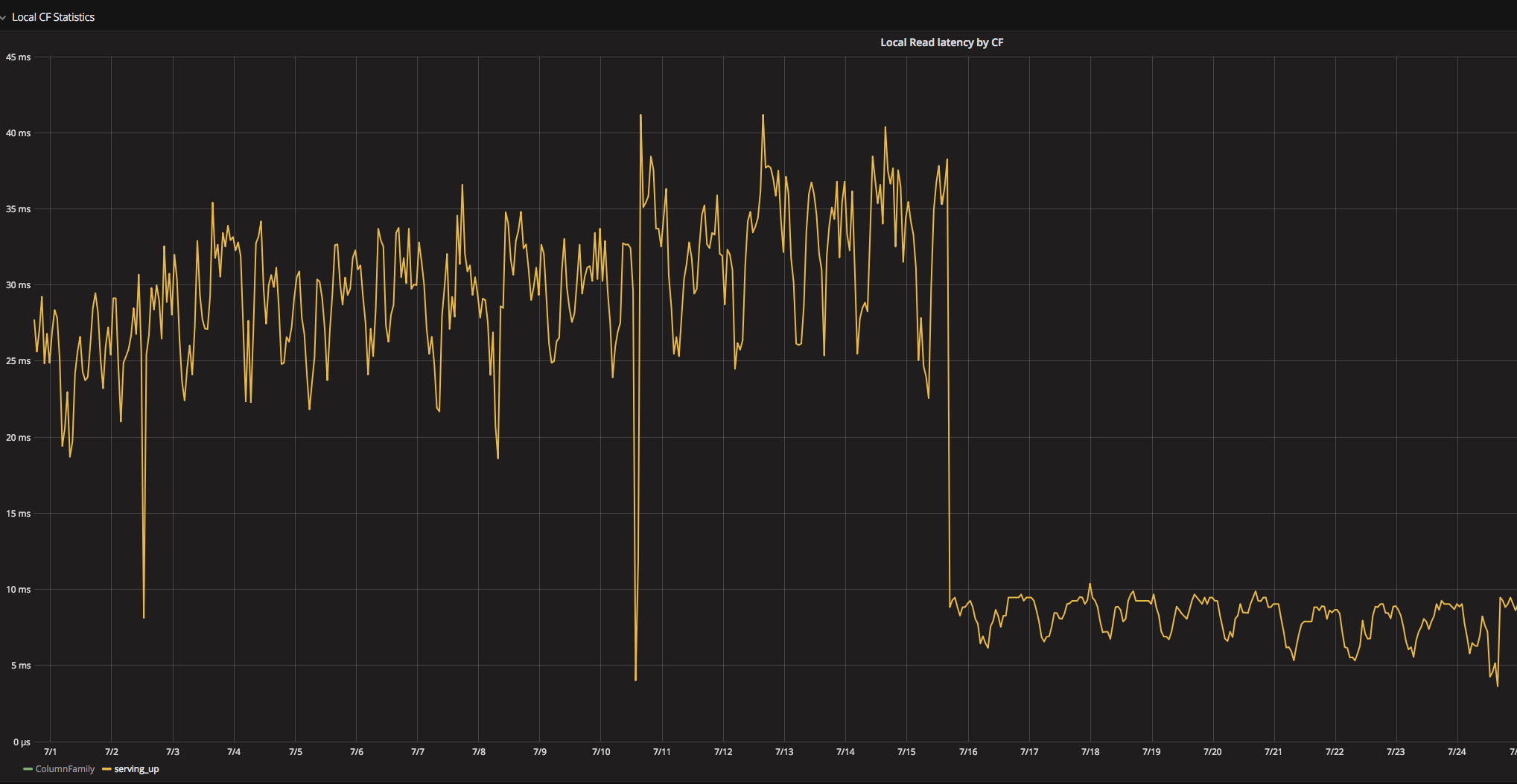
Page cache flush settings impact on local read latency
The results
So, in the end – what were our gains from Apache Cassandra 3.11?
Well aside from any new features we got lots of performance improvements, it’s a major storage savings which immediately transform into lower read latencies because more data fits into OS cache which improved a lot the clusters’ performance.
In addition, the newer storage format results in lower JVM pressure during reads (object creation ratio decreasing 1.5 – 2 times). The following image describe the decrease in the read latency in our datacenters (NY, CHI & SA) during load tests (LT) that we performed before and after the migration

Read latency before and after the migration
Another important aspect are new metrics exposed. Few interesting ones:
- Ability to identify consistency level requested for both reads and writes. This can be useful to track if occasionally the consistency level requested is not what would be expected for a given column family. For example, if QUORUM is requested instead of LOCAL_QUORUM due to a bug in app configuration.
- Metrics on the network messaging.
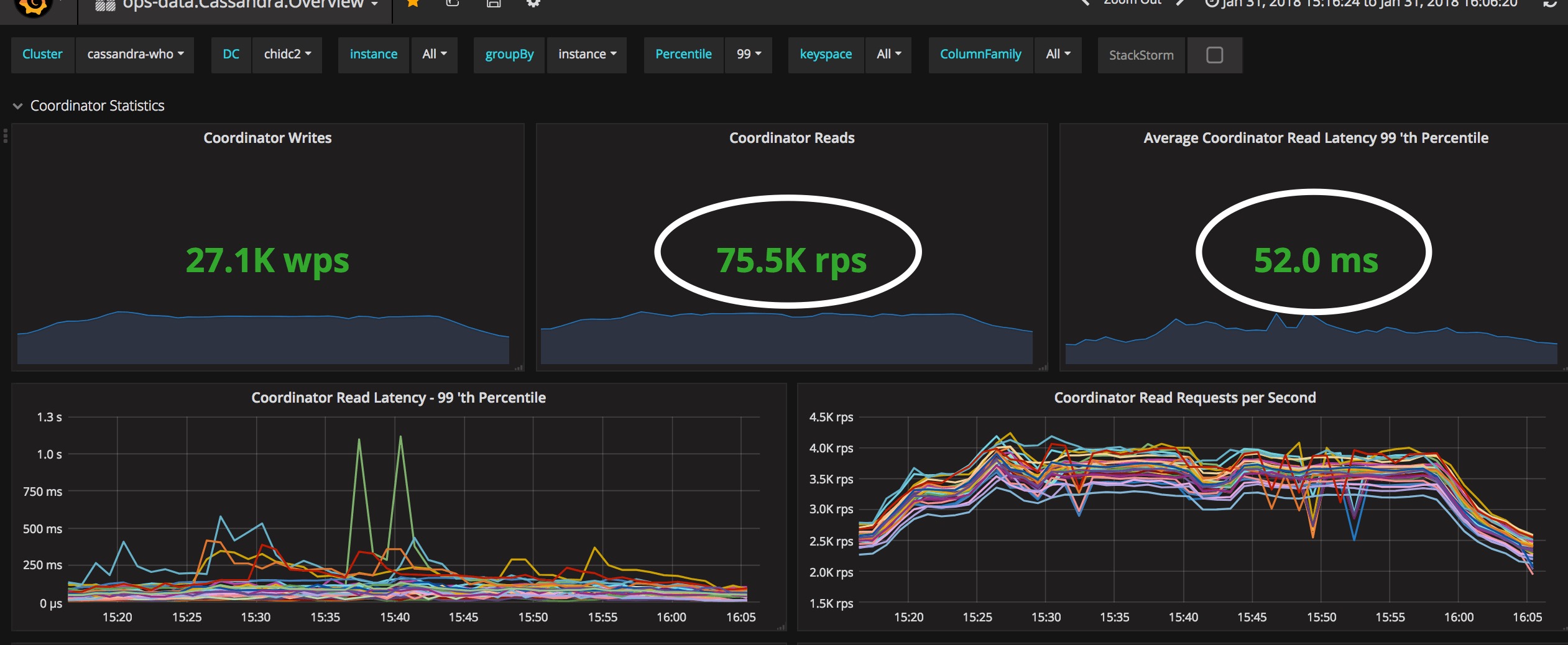
Read metrics before the migration
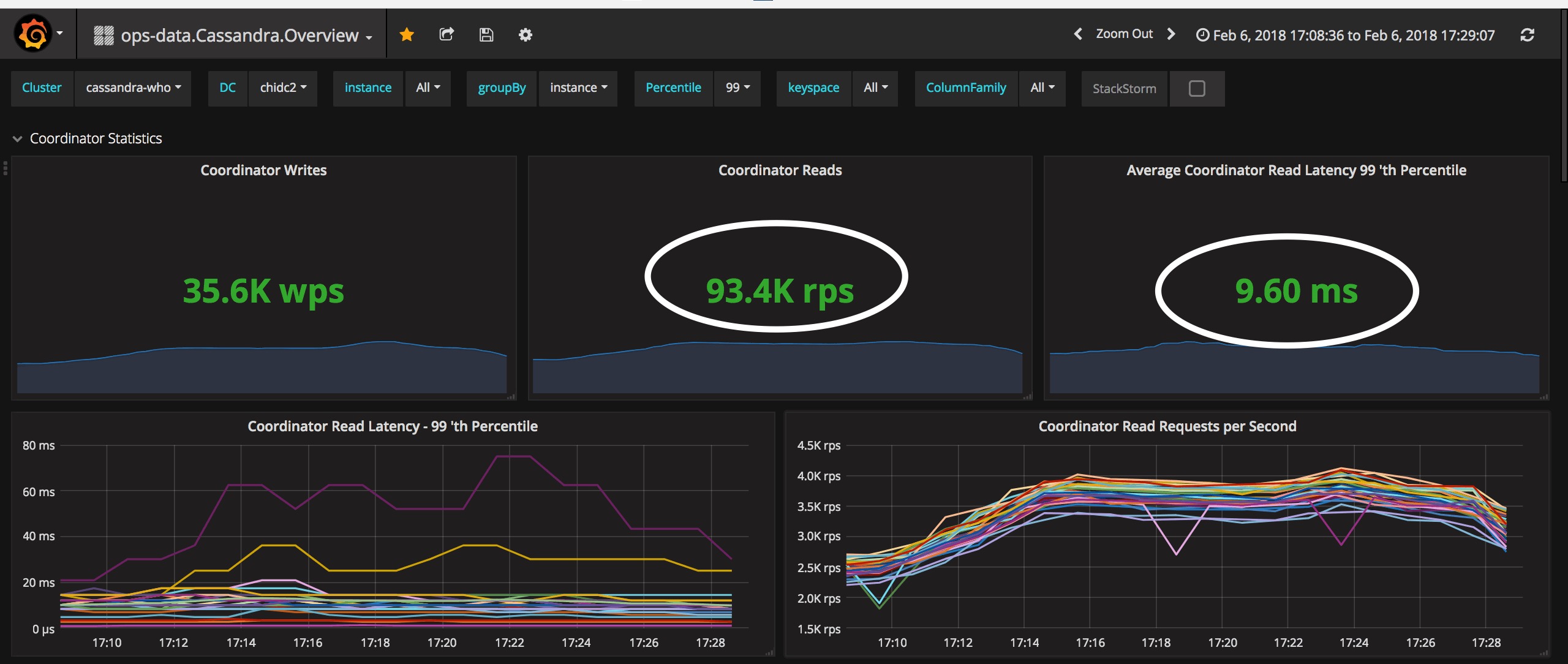
Read metrics after the migration
We did something that lots of people thought that it’s impossible, to perform such in-place migration in running production clusters. Although there were some bumps in the way, it’s totally possible to conduct an in-place upgrade of DSE 4.8.x to Apache Cassandra 3.11, while maintaining acceptable latencies and avoiding any cluster downtime.