 As a Data Engineer I’m dealing with Big Data technologies, such as Spark Streaming, Kafka and Apache Druid. All of them have their own tutorials and RTFM pages. However, when combining these technologies together at high scale you can find yourself searching for the solution that covers more complicated production use-cases.
As a Data Engineer I’m dealing with Big Data technologies, such as Spark Streaming, Kafka and Apache Druid. All of them have their own tutorials and RTFM pages. However, when combining these technologies together at high scale you can find yourself searching for the solution that covers more complicated production use-cases.
In this blogpost I’m going to share the knowledge I gained by combining Spark Streaming, Kafka and Apache Druid all together for building real time analytics dashboard, guaranteeing precise data representation.
Before we dive in…few words about Real Time Analytics
The Real-time analytics is a new trend in Big Data technologies, and usually has significant business effect. When analyzing fresh data, the insights are more precise. For example, providing real time analytics dashboard for Data Analysts, BI and Account Managers teams can help these teams to make fast decisions.
The commonly used architecture for real time analytics at scale is based on Spark Streaming and Kafka. Both these technologies are very well scalable. They run on clusters and divide the load between many machines. The output of Spark jobs can go to many various destinations, it depends on the specific use case and the architecture. Our goal was to provide the visual tool displaying real-time events. For this purpose we chose Apache Druid database.
Data visualization in Apache Druid
Druid is a high performance real-time analytics database. One of its benefits is the ability to consume real time data from Kafka topic and build powerful visualizations on top of it using Pivot module. Its visualizations enable running various ad-hoc “slice and dice” queries and get visual results quickly. It is very useful for analyzing various use cases, for example how specific campaigns perform in certain countries. Data is retrieved at real-time, with 1-2 minutes delay.
The architecture
So we decided to build our Real Time analytics system based on Kafka events and Apache Druid. We already had events in Kafka topic. However we could not just ingest them into Druid as is. We needed to add more dimensions to each event. We needed to enrich every event with more data in order to see it in Druid in a convenient way. Regarding the scale, we’re dealing with hundreds of thousands of events per minute, so we needed to use technology that can support these numbers. We decided to use Spark Streaming job for the enrichment of original Kafka events.
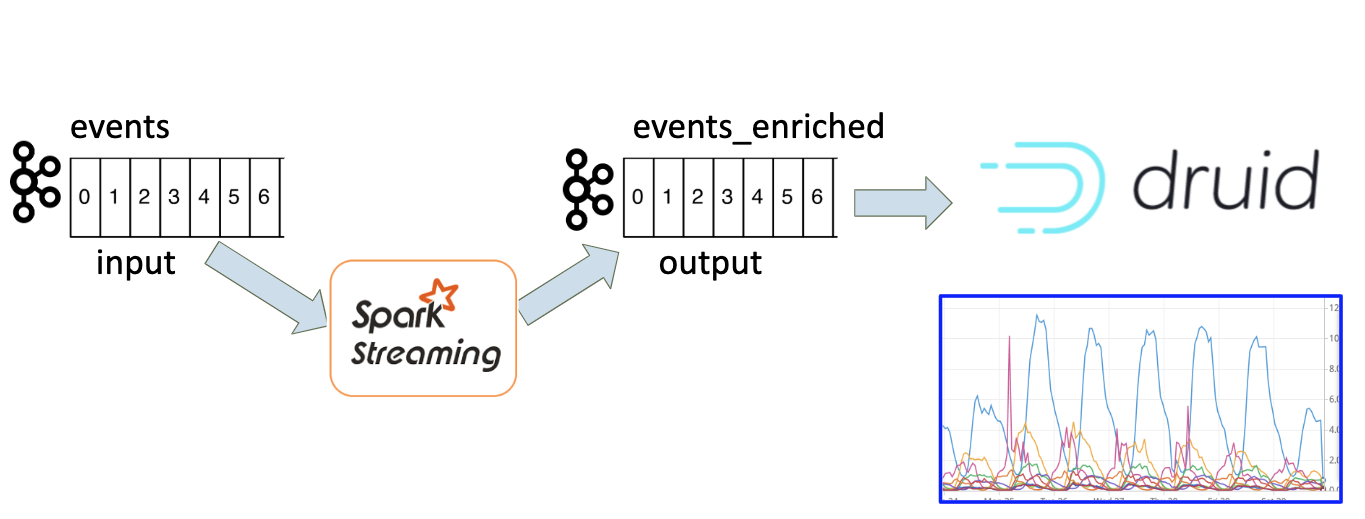
Figure 1. Real time analytics architecture
Spark Streaming job runs forever? Not really.
The idea of Spark Streaming job is that it is always running. The job should never stop. It constantly reads events from Kafka topic, processes them and writes the output into another Kafka topic. However, this is an optimistic view. In real life things are more complicated. There are driver failures in the Spark cluster, in which case the job is restarted. Sometimes the new version of spark application is deployed into production. What happens in this case? How does the restarted job read Kafka topic and process the events? Before we dig into these details, this figure shows what we see in Druid when the Spark Streaming job is restarted:
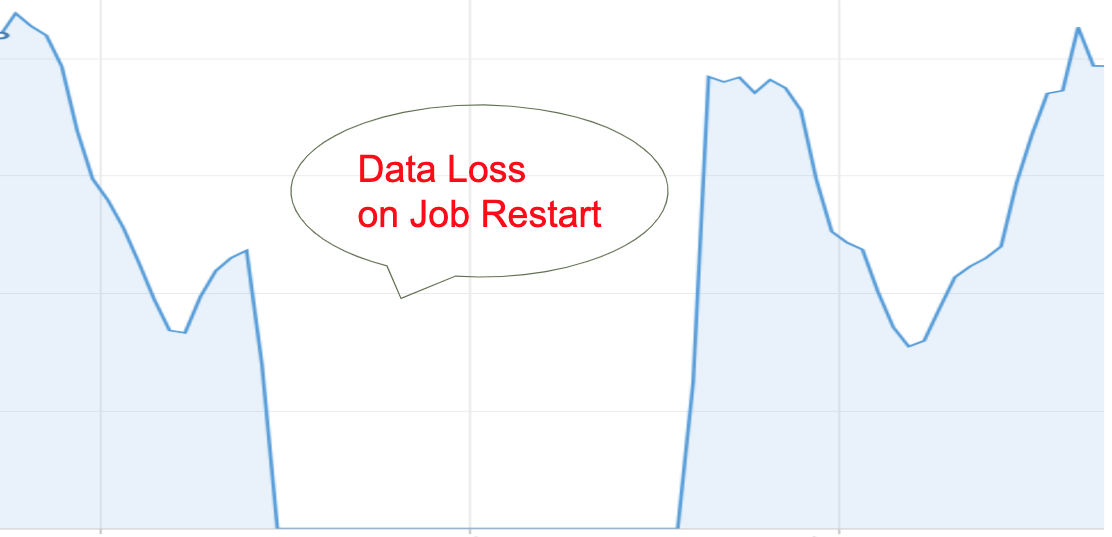
Figure 2. Data loss on job restart
It is definitely data loss!
What problem are we trying to solve?
We are dealing with Spark Streaming application which reads events from one Kafka topic and writes them into another Kafka topic. These events are visualized later in Druid. Our goal is to enable smooth data visualization during the restart of our Spark Streaming application. In other words, we need to ensure that no events are lost or duplicated during the Spark Streaming job restart.
It’s all about offsets
In order to understand why data is lost on jobs restart, we need to get familiar with some terms in Kafka architecture. Here you can find an official Kafka documentation. In a nutshell: events in Kafka are stored in topics; each topic has divided into partitions. Each record in a partition has an offset – a sequential number which defines the order of the record. When application consumes the topic, it can handle offsets in several ways. The default behavior is always to read from the latest offsets. Another option is to commit offsets, i.e. to persist offsets so the job can read the committed offsets on restart and continue from there. Let’s see our steps towards the solution, and get a deeper understanding of Kafka offsets management with each step.
Step#1 – auto commit offsets
The default behavior is always to read from the latest offsets. This will not work because when the job is restarted, there are new events in the topic. If the job reads from latest, it loses all messages that were appended during the restart, as can be seen in Figure 2. There is a “enable.auto.commit” parameter in Spark Streaming. Its value is false by default. Figure 3 shows the behavior after changing its value to true, running the Spark application and restarting it.

Figure 3. Data spike of job restart
We can see that using Kafka auto-commit feature causes a new effect. There is no “data loss” , however we now see duplicate events. There was no real “burst” of events. What actually happened is that auto commit mechanism commits offsets “from time to time” . There are many messages in the output topic that were not committed. After the restart the job consumes messages from the latest committed offsets and processes some of these events again. That’s why on the output we get a burst of events.
Clearly, incorporating these duplications into our visualization may mislead the business consumers of this data and have an impact on their decisions and trust in the system.
Step#2: Commit Kafka offsets manually
So we can’t rely on Kafka auto-commit feature. We need to commit Kafka offsets by ourselves. It order to do this, let’s see how Spark Streaming consumes data from Kafka topics. Spark Streaming uses an architecture called Discretized Streams, or DStream. DStream is represented by a continuous series of RDDs (Resilient Distributed Datasets), which is one of the Spark’s main abstractions. Most Spark Streaming jobs look something like this:
dstream.foreachRDD { rdd =>
rdd.foreach { record => process(record) }
}
In our case processing the record means writing the record to the output Kafka topic. So, in order to commit Kafka offsets we need to do the following:
dstream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
rdd.foreach { record => process(record)}
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}
This is a straight-forward approach and before we discuss it deeper let’s take a look at the big picture. Let’s assume that we handle offsets correctly. Namely, that offsets are saved after each processing of RDD. What happens when we stop the job? The job is stopped in the middle of the processing of RDD. The part of micro-batch is written to the output Kafka topic and is not committed. Ones the job runs again, it will process some messages for the second time and the spike of duplicate messages will appear (as before) in Druid:

Figure 4. Data spike on job restart
Graceful Shutdown
Turns out there is a way to ensure a job is not killed during an RDD processing. It is called a “Graceful Shutdown”. There are several blog posts describing how you can kill your Spark application gracefully, but most of them relate to old versions of Spark and have many limitations. We were looking for a “safe” solution that works for any scale and does not depend on a specific Spark version or operating system. To enable Graceful Shutdown, the Spark context should be created with the following parameters:
spark.streaming.stopGracefullyOnShutdown = true.
This instructs Spark to shut down StreamingContext gracefully on JVM shutdown rather than immediately.
In addition, we need a mechanism to stop our jobs intentionally, for example when deploying a new version. We’ve implemented the first version of this mechanism by simply checking the existence of an HDFS file that instructs the job to shut down. When the file appears in HDFS, the streaming context will stop with the following parameters:
ssc.stop(stopSparkContext = true, stopGracefully = true)
In this case the Spark application stops gracefully only after all received data processing is completed. This is exactly what we need.
Step #3: Kafka commitAsync
Let’s recap on what we have so far. We intentionally commit Kafka offsets in each RDD processing (using Kafka commitAsync API) and we use spark graceful shutdown. Apparently, there was another caveat. Digging into the documentation of Kafka API and Kafka commitAsync() source code, I’ve learned that commitAsync() only puts the offsetRanges into a queue, which is actually processed only in the next loop of foreachRDD. Even if the Spark job is stopped gracefully and finishes processing of all its RDDs, the offsets of last RDD are actually not committed. To solve this problem, we’ve implemented a code that persists Kafka offsets synchronously and does not rely on Kafka commitAsync(). For each RDD we then stored the committed offsets in an HDFS file. When the job starts running again, it loads the offsets file from the HDFS and consumes Kafka topic from these offsets and on.
Here, it works!
It was only the combination of a graceful shutdown and a synchronous storage of Kafka offsets that provided us with the desired result. No data loss, no data spikes during restarts:
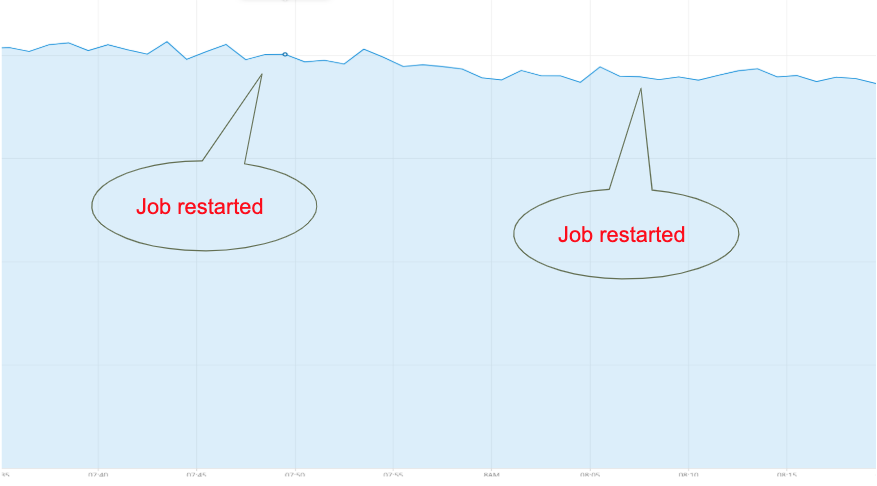
Figure 5. No data loss of spikes during Spark job restart
Conclusion
Solving the integration problem between Spark Streaming and Kafka was an important milestone for building our real-time analytics dashboard. We’ve found the solution that ensures stable dataflow without loss of events or duplicates during the Spark Streaming job restarts. We now have the trustworthy data which is visualized in Druid. Thanks to this, we’ve added more types of events (Kafka topics) into Druid and built real time dashboards. These dashboards provide insights for various teams, such as BI, Product and Customer Support. Our next goal is to utilize more features of Druid, like new analytical functions and alerts.
I am a Data Infrastructure Engineer in Outbrain's platform group, developing solutions for large-scale data delivery and data processing systems.