
At Outbrain we work at a fast pace trying to combine the challenges of developing new features fast, while also maintaining our systems so that they can cope with the constant growth of traffic. We deliver many changes on a daily basis to our production and testing environments so our velocity is much affected by our DevOps tools. One of the tools we use the most is the deployment tool since every new artifact must be deployed to simulation and staging environments and pass its test before it can be deployed to production. The simulation environment is used for running E2E integration tests. These tests simulate real use cases and they involve all relevant services. The staging environment is actually a single production machine (AKA a canary machine) which receives a small portion of the traffic in production. It allows us to make sure the new version is working properly in the production environment before we deploy it to the rest of the production servers. In this session, you’ll find out how we increased velocity with a safe automatic deployment of high scale services.
Our deployment flow
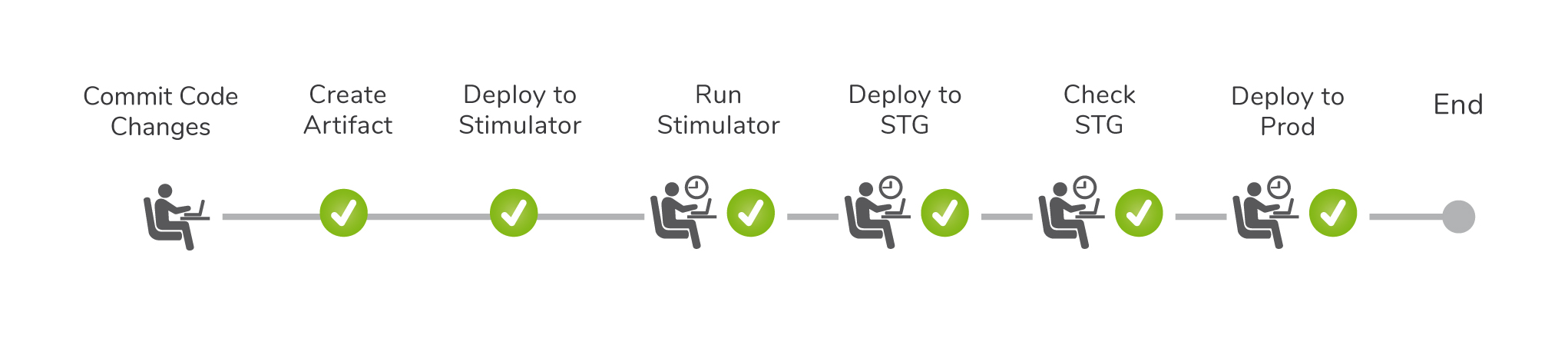 The illustration above depicts the flow each code change must pass until it arrives in production.
The illustration above depicts the flow each code change must pass until it arrives in production.
A developer commits code changes and triggers a “build & deploy” action that creates an artifact for the requested service and deploys it to our simulators servers. Once an hour, a build in TeamCity runs the simulation tests of our services.
If the developer doesn’t want to wait for the periodic run, they need to run the simulation tests manually. Once the build passes, the developer is allowed to deploy the artifact to the staging server. At this point, we verify that the staging server behaves properly by reviewing various metrics of the server, and by checking the logs of that server.
For instance, we verify that the response time hasn’t increased and that there are no errors in the log. Once all these steps are completed, the new version is deployed to all production servers. This whole process can take 30-45 minutes.
As one can see, this process has a lot of problems:
- It requires many interventions of the developer.
- The developer either spends time waiting for actions to complete in order to trigger the next ones or they suffer from context switches which slow them down.
- The verification of the version in staging is done manually hence
- It’s time-consuming.
- There is no certainty that all the necessary tests are made.
- It’s hard to share knowledge among team members of what the expected result of each test is.
The new automatic pipeline
Recently we have introduced a pipeline in Jenkins that automates this whole process. The pipeline allows a developer to send code changes to any environment (including production) simply by committing them into the source control while ensuring that these changes don’t break anything.
The illustration below shows all stages of our new pipeline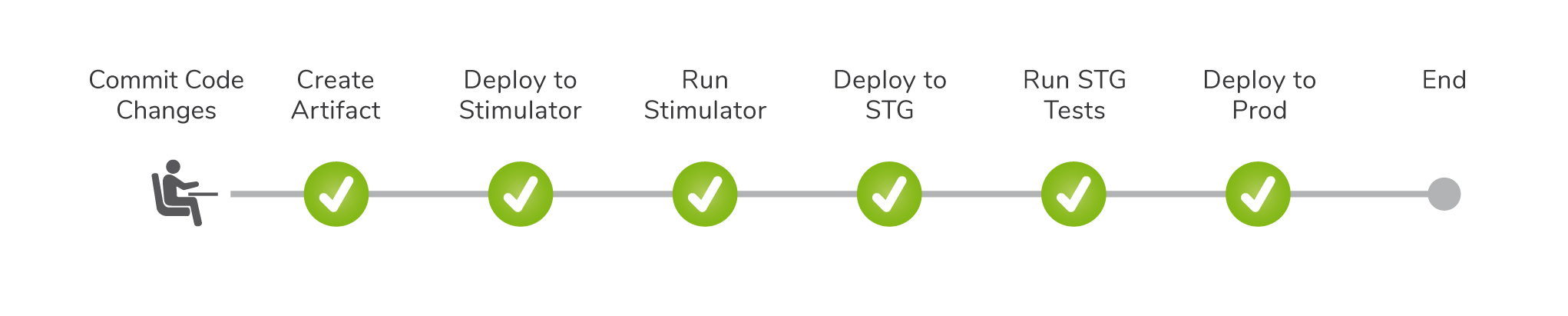
Aside from automating the whole process, which was relatively easy, we had to find a way to automate the manual tests of our staging environment. As mentioned, our staging servers serve real requests coming from our users.
Some of our services handle around 2M requests per minute so any bad version can affect our customers, our users, and us very quickly. Therefore we would like to be able to identify bad versions as soon as possible. To tackle this issue, our pipeline starts running health tests on our staging servers 5 minutes after the server goes up since sometimes it takes time for the servers to warm up.
The tests which are executed by TeamCity, pull a list of metrics of the staging server from our Prometheus server and verify that they meet the criteria we defined. For example, we check that the average response time is below a certain number of milliseconds. If one of these tests fail, the pipeline fails. At that point, the developer who triggered the pipeline receives a notification e-mail so that they can look into it and take the decision whether the new version is bad and revert it, or maybe the tests need some more fine-tuning and the version is okay to deploy to the rest of the servers.
The pipeline ends when the new version is deployed to production but this doesn’t necessarily mean that the version is 100% okay, although the chances that the version is not okay at this stage are low.
For the purpose of ensuring our production servers function properly, many periodic tests constantly monitor the servers and trigger alerts in case of a failure and allow us to react fast and keep our services available.
What we gained
- The automated deployment process ensures the quality of our deliveries and that they don’t break our production servers.
- Reduction of time developers spends on DevOps tasks.
- The decision whether a version in staging is okay is more accurate as it is based on comparable metrics and not on a subjective decision of the developer.
- The developer doesn’t need to remember which metrics to check for each service in order to tell whether a service functions properly.