Previously on our second episode of the trilogy “Hadoop Research Journey from bare metal to Google Cloud – Episode 2”, we covered the POC we had.
In this episode we will focus on the migration itself, building a POC environment is all nice and easy, however migrating 2 PB (the raw part out of 6 PB which include the replication) of data turned to be a new challenge. But before we jump into technical issues, lets start with the methodology.
The big migration

We learned from our past experience that in order for such a project to be successful, like in many other cases, it is all about the people – you need to be minded to the users and make sure you have their buy-in.
On top of that, we wanted to complete the migration within 4 months, as we had a renewal of our datacenter space coming up, and we wanted to gain from the space reduction as result of the migration.
Taking those two considerations in mind, we decided that we will have the same technologies which are Hadoop and Hive on the cloud environment, and only after the migration is done we would look into leveraging new technologies available on GCP.
Now after the decision was made we started to plan the migration of the research cluster to GCP, looking into different aspects as:
- Build the network topology (VPN, VPC etc.)
- Copy the historical data
- Create the data schema (Hive)
- Enable the runtime data delivery
- Integrate our internal systems (monitoring, alerts, provision etc.)
- Migrate the workflows
- Reap the bare metal cluster (with all its supporting systems)
All in the purpose of productizing the solution and making it production grade, based on our standards. We made a special effort to leverage the same management and configuration control tools we use in our internal datacenters (such as Chef, Prometheus etc.) – so we would treat this environment as yet just another datacenter.
Copying the data

Sound like a straightforward activity – you need to copy your data from location A to location B.
Well, turns out that when you need to copy 2 PB of data, while the system is still active in production, there are some challenges involved.
The first restriction we had, was that the copy of data will not impact the usage of the cluster – as the research work still need to be performed.
Second, once data is copied, we also need to have data validation.
Starting with data copy
- Option 1 – Copy the data using Google Transfer Appliance
Google can ship their transfer appliance (based on the location of your datacenter), that you would attach to the Hadoop Cluster and be used to copy the data. Ship it back to Google and download the data from the appliance to GCS.
Unfortunately, from the capacity perspective we would need to have several iterations of this process in order to copy all the data, and on top of that the Cloudera community version we were using was so old – it was not supported.
- Option 2 – Copy the data over the network
When taking that path, the main restriction is that the network is used for both the production environment (serving) and for the copy, and we could not allow the copy to create network congestion on the lines.
However, if we restrict the copy process, the time it would take to copy all the data will be too long and we will not be able to meet our timelines.
Setup the network
As part of our network infrastructure, per datacenter we have 2 ISPs, each with 2 x 10G lines for backup and redundancy.
We decided to leverage those backup lines and build a tunnel on those lines, to be dedicated only to the Hadoop data copy. This enabled us to copy the data in relatively short time on one hand, and assure that it will not impact our production traffic as it was contained to specific lines.
Once the network was ready we started to copy the data to the GCS.
As you may remember from previous episodes, our cluster was set up over 6 years ago, and as such acquired a lot of tech debt around it, also in the data kept in it. We decided to take advantage of the situation and leverage the migration also to do some data and workload cleanup.
We invested time in mapping what data we need and what data can be cleared, although it didn’t significantly reduce the data size we managed to delete 80% of the tables, we also managed to delete 80% of the workload.
Data validation
As we migrated the data, we had to have data validation, making sure there are no corruptions / missing data.
More challenges on the data validation aspects to take into consideration –
- The migrated cluster is a live cluster – so new data keeps been added to it and old data deleted
- With our internal Hadoop cluster, all tables are stored as files while on GCS they are stored as objects.
It was clear that we need to automate the process of data validation and build dashboards to help us monitor our progress.
We ended up implementing a process that creates two catalogs, one for the bare metal internal Hadoop cluster and one for the GCP environment, comparing those catalogs and alerting us to any differences.
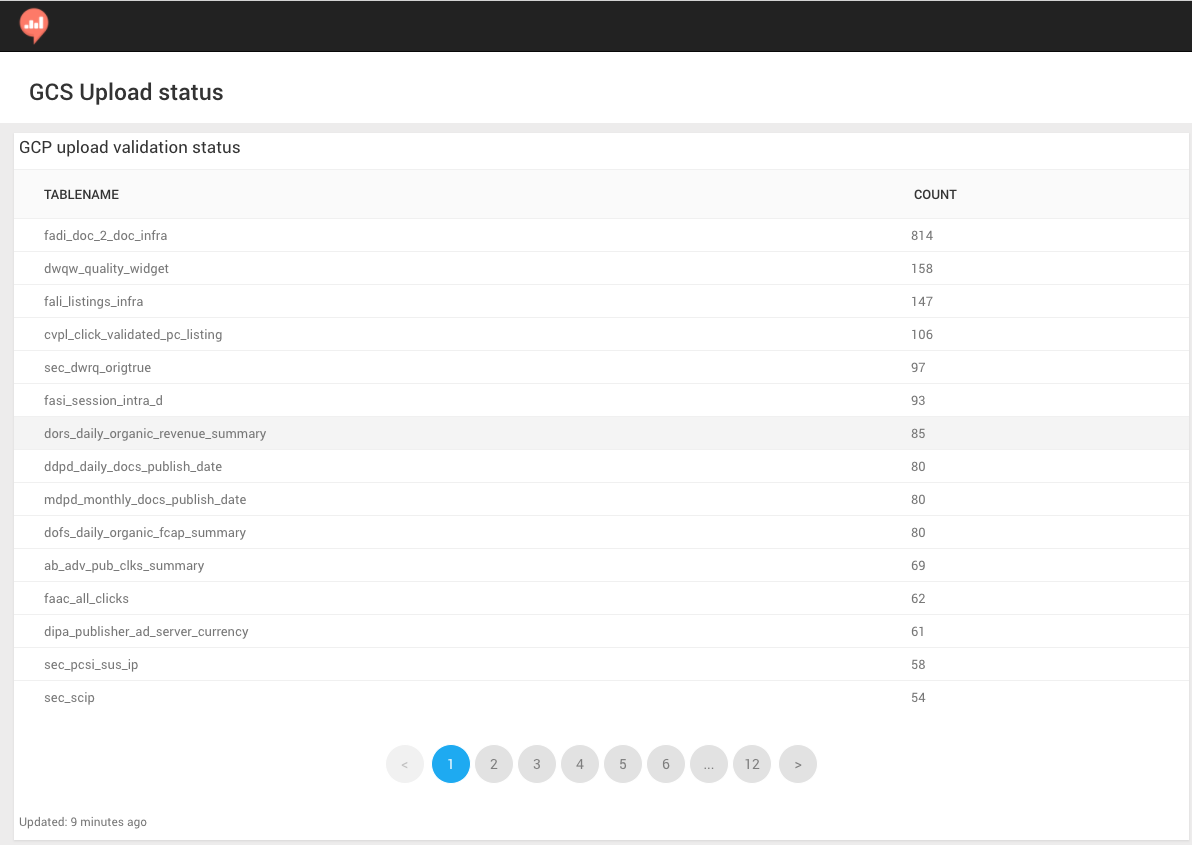
This dashboard shows per table the files difference between the bare metal cluster and the cloud
In parallel to the data migration, we worked on building the Hadoop ecosystem on GCP, including the tables schemas with their partitions in Hive, our runtime data delivery systems adding new data to the GCP environment in parallel to the internal bare metal Hadoop cluster, our monitoring systems, data retention systems etc.
The new environment on GCP was finally ready and we were ready to migrate the workloads. Initially, we duplicated jobs to run in parallel on both clusters, making sure we complete validation and will not impact production work.
After a month of validation, parallel work and required adjustments we were able to decommission the in-house Research Cluster.
What we achieved in this journey
- Upgraded the technology
- Improve the utilization and gain the required elasticity we wanted
- Reduced the total cost
- Introduced new GCP tools and technologies
Epilogue
This amazing journey lasted for almost 6 months of focused work. As planned the first step was to use the same technologies that we had in the bare metal cluster but once we finished the migration to GCP we can now start planning how to further take advantage of the new opportunities that arise from leveraging GCP technologies and tools.
Director of Data Engineering @ Outbrain's Platform Group, developing large-scale data systems for Outbrain's content recommendations platform.